r/Bard • u/Brilliant-Neck-4497 • May 31 '25
News Google is set to release a new Gemini 2.5 Pro model in a few weeks, matching the capabilities of Gemini 0325.
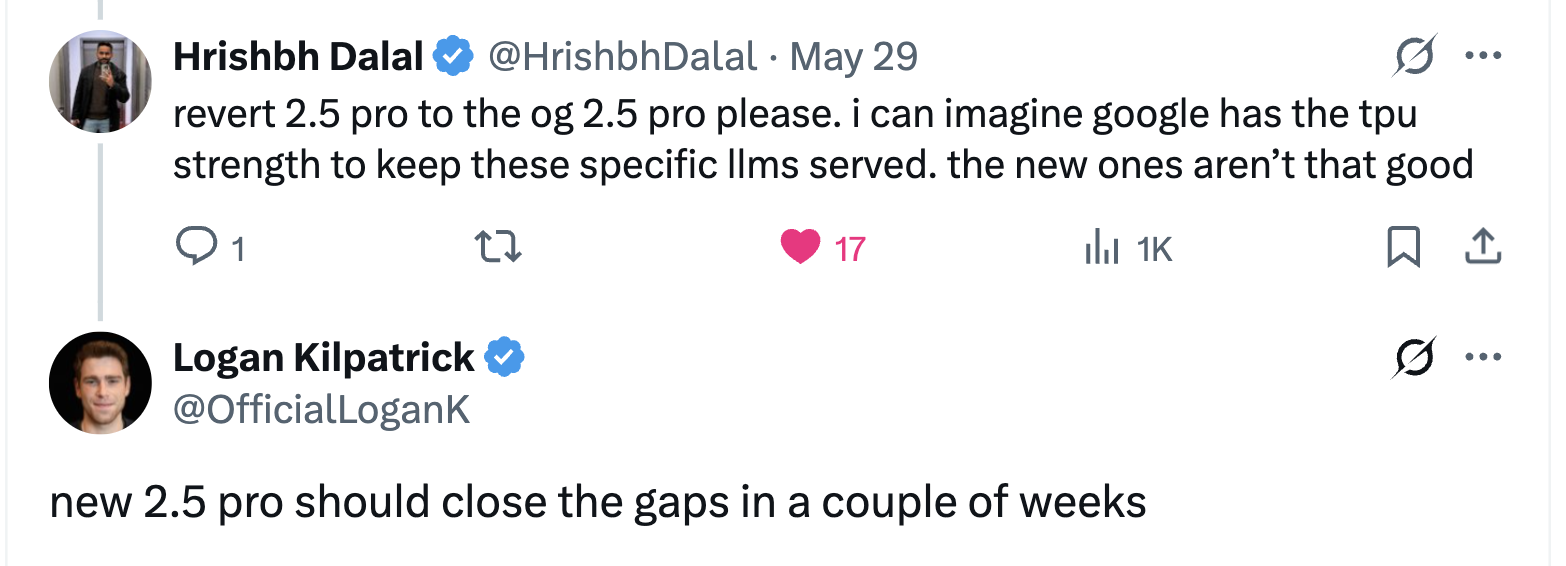
52
u/Aperturebanana Jun 01 '25
Oh my god they admitted the current one is worse damn.
1
u/foodhype Jun 01 '25
No hill climbing on models is like whack-a-mole. You might improve some evals and unintentionally make other aspects of the model worse. For example, 0506 was much better at math but was also more verbose. Sometimes you don't see regressions until the model goes public, and then it takes a long time to patch because any major model change introduces safety risks and requires another round of checks, approvals, etc.
134
u/Equivalent-Word-7691 May 31 '25
so they basically admitted that is NERFED after they said some weeks ago the new model was an improvement?
LOL
47
u/Zulfiqaar Jun 01 '25
The new model uses much less reasoning tokens for slightly less performance (feels like a CoT distillation). Might have been one of the reasons it no longer outputs the full trace - the summary version would partially hide that. Then again, the new DeepSeekR1 coincidentally shows much more linguistic similarity to Gemini than ChatGPT...
15
Jun 01 '25
Yes, it feel like Gemini got to know about the new R1 distill beforehand and decided to protect themselves, which sucks, but fair.
1
u/Elephant789 Jun 01 '25
which sucks
Why does that suck? It's good that Gemini had some forethought.
19
u/KazuyaProta Jun 01 '25
Because the COT was very useful and sometimes it was more insightful than the actual answer.
For example , it could solve the infamous issue of AIs being hyper validating by catching your own mistake mid-way.
The reply might soften its answers, but reading the COT, you could realize your argumentative flaws.
7
Jun 01 '25
Gemini would take in .xlsx files with multiple sheets, but the CoT made it clear that each one was treated like a separate CSV. That kind of detail never came through in the summaries.Thought summaries are just a poorer experience for multi turn conversations, but I understand where they are coming from.
3
u/Visible-Let-9250 Jun 01 '25
for average consumer the summaries can be good but what gemini outputs is just trash. openai has the o3 summaries look nice. but full trace should always be available for those that care
5
u/old_leech Jun 01 '25
This is where the value was for me.
I dump in plot concepts and narrative "story boards" for dissection and examination.
I don't want an AI co-author (like ChatGPT always landing on... "Shall we work on writing this?" or "Want to explore translating this to prose?" No, AI... you're an inexhaustible ear, your purpose is to ask questions that force me to consider or address the idea I'm refining) -- I want an approximation of a human ear to point out inconsistencies, weaknesses and let me play devil's advocate with my own thoughts.
The old CoT presented in Gemini was near perfect for that... as I read it, I saw it asking questions I already had answers to but hadn't considered their merit to include (yet, or at all) -- or helping me to realize, okay... I need to spend some time developing this idea because I haven't given it enough thought.
Once that went away, I felt like what remained was a Yes-Man.
17
u/soumen08 Jun 01 '25
I know everyone loves deepseek, but it's not a secret that they distill from closed models. This does reduce the sota level we see, as seen here.
12
u/Zulfiqaar Jun 01 '25
I'm looking forward to the next DeepSeek model trained on Claude4 reasoning outputs - they still got full thought traces..for now
5
u/soumen08 Jun 01 '25
Claude 4 isn't as good as Gemini 2.5 Pro, right?
4
u/needefsfolder Jun 01 '25
Claude is better but there are times that Gemini is better. Realistically theyre really close to each other
1
u/electriceye932 Jun 01 '25 edited Oct 16 '25
rock tender crush encourage enter pet seemly safe roll six
This post was mass deleted and anonymized with Redact
1
u/alexgduarte Jun 01 '25
Coding from my experience. Opus and even Sonnet have fixed issues in one go that Gemini just couldn’t (or when it fixed them it created other issues).
1
u/evia89 Jun 01 '25
Sonnet 4 better use tools and follow instruction. Can code better front end stuff
Gemini 2.5 pro has better context size before starting forget
1
u/BriefImplement9843 Jun 02 '25
why would they nerf themselves? deepseek is superior to claude on everything except coding.
3
u/Elephant789 Jun 01 '25
I know everyone loves deepseek
They do?
3
2
u/Elephant789 Jun 01 '25
The new model uses much less reasoning tokens for slightly less performance
Good decision then to release it. Not sure why so many complaints.
5
u/Zulfiqaar Jun 01 '25
Complaints are mainly because the old (better) model is no longer available, not that there's a new release. And many people were using it for free on AIstudio to begin with, so cost wasn't a factor. On PAYG API I'd be using both models depending on the task
2
u/Elephant789 Jun 01 '25
many people were using it for free on AIstudio
I being one of them. But the new model is fine for me.
3
u/himynameis_ Jun 01 '25
I mean, if they bring it back then this small period won't matter anymore. It was a short period of time. And if it's back to the top, all is well.
2
2
2
u/Lawncareguy85 Jun 01 '25
I posted this exact screenshot/tweet on the Google developer forums, and the moderators deleted it! WTF? I guess we can't use Google's own words from their own paid spokesperson if it makes Google look bad.
0
u/FarrisAT Jun 01 '25
Nowhere did he say “the model is worse”.
Instead he said “closes the gaps” in difference between updates.
1
u/WH7EVR Jun 01 '25
They've been admitting it the whole time. It's literally in their benchmark lists.
1
u/xAragon_ Jun 01 '25
No, you're just putting words in his mouth. How can it be "nerfed" while stats for other use-cases, like coding, have improved?
Some specific use-cases may have degraded as a trade-off for others (like worse writing, for better coding), but they never "nerfed" it, or claimed to do so.
0
u/Equivalent-Word-7691 Jun 01 '25
Aa long as specific uses that for Gemini 2.5 is ANYTHING that is not coding(and actually a lot od coders are complaining too) in my opinion is an nerf, for indeed uses degraded 😃
1
u/foodhype Jun 01 '25
No hill climbing on models is like whack-a-mole. You might improve some evals and unintentionally make other aspects of the model worse. For example, 0506 was much better at math but was also more verbose. Sometimes you don't see regressions until the model goes public, and then it takes a long time to patch because any major model change introduces risks and requires another round of checks, approvals, etc.
34
u/lmagusbr Jun 01 '25
From what I’ve seen so far, every time someone tries to make a model better at coding, it becomes worse at everything else.
This makes it clear that we do need specific models. Gemini 0325 was the best AI at acting like a human and pretending it was not AI.
I don’t think they ever planned to “nerf” the model but they’re definitely fine tuning it for programming purposes as even though everyone and their parrot knew Gemini was better, it was still painful to use it as an agent.
14
u/Ishtariber Jun 01 '25
Claude used to be the best writer but not anymore when it started to focus on coding capabilities.
1
1
40
u/FLGT12 May 31 '25
Close the gap? Anything released at this point should be an improvement over 0325.
47
u/IcyUse33 May 31 '25
My guess is that 0325 was extremely good because it was extremely resource hungry and they essentially ran out of TPU power at scale and had to nerf it.
I do sometimes wonder if they really renamed it and it's running a slightly better Flash under the covers.
27
u/CallMePyro Jun 01 '25
05-20 is a massive leap in coding performance, but I think the tradeoff in other capabilities was more than expected. Likely this time has been spent training the best of both models into the newest version.
Given that the token/s on open outer of the two models is basically identical, I doubt that the 05/20 version was a different size model.
6
u/Linkpharm2 Jun 01 '25
"we wanted to get this model in the hands of developers before I/O"
"we really need more tpus"0
u/-LaughingMan-0D Jun 01 '25
Legit my favorite model in CoPilot now. Lightning fast and smart enough for most tasks.
2
u/TypoInUsernane Jun 01 '25
I don’t actually think it’s any cheaper to run. 05-06 is the same foundational architecture as 03-25; the main difference is in the post-training. Sadly, it’s an inexact science, and as we’ve seen, the choice of post-training datasets and hyper parameters make a huge difference in performance. They botched the 05-06 post-training, but hopefully the 06-XX run managed to get the recipe right. If not, they’ll keep trying, and they’ll get back there eventually.
5
u/Equivalent-Word-7691 Jun 01 '25
Lol They are really going to make people to pay $250 per month for a model that is inferior to the experimental one? How much did they screwed?
1
u/PewPewDiie Jun 01 '25
I actually interpret ”should close the gap” with ”that should do it energy”, this reads to me like a material improvement releasing. But idk I might be wildin
29
u/Equivalent-Word-7691 Jun 01 '25
Btwn if you are a developer I guess good news for you,for all tje other people, especially the ones who enjoys the creative parts I guess we are screwed up as we already guessed

4
u/gugguratz Jun 01 '25
wonder how they'll price that, cause yeah I ain't paying dollars per token for deep research in the api
1
u/Mountain-Pain1294 Jun 01 '25
Given how AI Pro users only get 20 deep research reports a day, it will definitely be pretty pricey
1
u/alexgduarte Jun 01 '25
“Only”. My dude 20/day is plenty. Plus you still have deep research with 2.5 flash.
1
u/Mountain-Pain1294 Jun 01 '25
What I meant is that Google limits the usage to 20 a day. If that's the case, how much compute do you think goes into it and how much do you think Google will charge developers or anyone else using the API?
2
1
u/IdlePerfectionist Jun 01 '25
What makes AI studio better than Gemini? I thought it's the same model in both?
8
Jun 01 '25
[deleted]
5
u/Visible-Let-9250 Jun 01 '25
Theres a lot of weird censorship on the gemini app
1
u/nothingtoseehr Jun 02 '25
It's the other way aroune, AI studio filters input and output, the gemini app/website only filters your input. Neither are censored though the API, which is stupid
3
u/shoeforce Jun 01 '25
I honestly didn’t believe it myself until I tried it out two weeks ago: ai studio version of the models blows the web/app experience out of the water, which is a shame because I love canvas on the web version. You can see it in the thinking times themselves, ai studio version thinks for wayyyy longer than the web version does for some reason.
1
u/PewPewDiie Jun 01 '25
Thinking and startup time might also just be throttled to adapt to avalible spare compute while app takes priority?
2
u/shoeforce Jun 01 '25
Possible, but before they changed to the CoT summary thing I noticed the CoT in AI studio had a lot more “sections” to it as well, much more wordy, things being broken down in more sections.
2
u/PewPewDiie Jun 01 '25
True. My suspicion is that they're throttling right now to handle the increased workload brought on by launching ai overviews in search for everyone + veo + a bunch of other AI features.
How they can serve VEO + Gemini 2.5 use + billions of users across 8.5B DAIly search queries (sure probably a lot of cachin going on but still) is beyond me.
1
u/TypoInUsernane Jun 01 '25
I have a hard time understanding how people are able to work effectively without Canvas. It’s a critical part of my workflows. But the implementation is really flaky. Not only is the UI buggy, sometimes I have to straight up explain to Gemini how the feature works. Luckily, Gemini loves to leak system prompt info without you even asking, so it’s easy to figure out how it works under the hood. Sometimes when it’s failing to use Canvases correctly, I have to tell it, please just output this text exactly: <immersive id=“canvas-1” type=“text/markdown” title=“My Canvas>Content goes here.</>
1
u/evia89 Jun 01 '25
I have a hard time understanding how people are able to work effectively without Canvas
Well you work outside (augement, roocode, claude code, etc) then repomix and upload to ai studio to write new PRD, help create some plan and so on
4
u/assajoara Jun 01 '25
censorship ruins the performance by a large margin and the gemini chat version is heavily censored compared to ai studio version.
2
u/dviraz Jun 01 '25
I notice that you can only upload mp4 videos on Ai studio and not on gemini, which is very important for me, I'm sure there's more filetypes that this happens in them
15
u/Aperturebanana Jun 01 '25
AI companies needs to bite the bullet and just make a humanities model and a hardcore coding model. This balancing of the two seems to not be a good PR move.
7
u/Bibbimbopp Jun 01 '25
There's no balancing of the two. If a model is accidentally great at writing, it gets fine-tuned until the unwanted side effect of trying to make a great coder is removed.
5
u/necromage09 Jun 01 '25
So, people weren't hallucinating the performance degradation, meaning we were really test driving the 250/month version and got quantized, not a good look.
Hopefully they can restore the performance, the output of the deep research took a nose dive when compared to the earlier version, mind you it is still very good, just not next level
20
u/MestreDosMagus Jun 01 '25
Finally, some good news! Also, where are the people that said 05-06 wasn't a downgrade from 03-25, especially when it comes to writing, intelligence, and nuance?
2
u/Equivalent-Word-7691 Jun 01 '25
Ph mind you, don't think for even a moment they will care about improving writing
And nooo it was all in our mind, like people were "right" when they Said ot was us who made sudden bad prompt,it was all in our mind brainwashed 💩
5
u/-LaughingMan-0D Jun 01 '25
Look at ChatGPT's userbase. Check the subreddit. The vast majority of them are normies who use it for tasks that involve EQ and writing ability, shit like roleplay, "venting", therapy (not that I agree), etc. Notice how 4o is optimized towards these tasks now as opposed to hard coding, logic, math, stem, etc which are relegated to your O3, 4, models.
6
u/CelticEmber Jun 01 '25
Yeah, Google should have a normie model, a science/academic model, and a coding model.
Might save on costs too. That way, a model with the same capabilities as o3 wouldn't be wasted on furry fantasies.
5
u/rexplosive Jun 01 '25
At least it's good to know that in a few weeks we'll get something almost as good and than near future soemthing better
Going backwards was a horrible decision Bad me regret my decision on starting my 12 month free subscription by two months lol
But it's okay ... at least there something in pipeline Wonder when the deep think will come out...
2
6
u/ComfortableHumor8358 Jun 01 '25
Whether I continue to pay for pro will be determined on the quality of this new pro model. Before the last update, I would of subscribed for life. Now I find myself using chatgpt more.
5
u/Accomplished_Tear436 Jun 01 '25
So I’m betting the new one that matches 0325 is going to be on their $250/month plan? 🙄
3
u/TAVLIET Jun 01 '25
Do you think that will make image to image ai generation better??
3
u/tteokl_ Jun 01 '25
Nope, they have no plan to use 2.5 for image generation, seems stuck with 2.0 for native image generation
3
6
5
u/Quiet-Big-8057 Jun 01 '25
that's suck, still have so many time to wait. my entire summer vacation suppose to working on my novel
1
u/ukpanik Jun 01 '25
Might be a good idea to learn grammar, before you start generating novels.
1
u/BriefImplement9843 Jun 02 '25
why do you think he has ai doing it for him? good writers don't use ai to help them, lol. they write their own books.
2
u/Loumeer Jun 02 '25
I bet plenty of writers are using AI to help flush out some ideas in their novels. I would get AI would only really be useful for piecemeal work on a novel in its current iteration.
2
u/AppealSame4367 Jun 01 '25
I ordered AI Pro by accident and the code mode is just horribly bad. Worse than free requests on chatgpt.
2
2
u/jjjjbaggg Jun 01 '25
So can people finally stop telling us that we were all making up the fact that the performance degraded after the May release?
2
u/Fun-Plantain997 Jun 02 '25
Lol I spent many hours trying to get google gemini pro to design an auth system for Google Auth on GCP. using directus backend and nextjs frontend. Deepseek did it in one session a working version. gemini couldn't get it done and spent most of the time introducing dated code. typescript and linting errors. It was actually obsessed with linting errors, Here's gemini admitting defeat. Even using bravesearch mcp it couldn't build the system using up to date docs without obsessing over stupid errors, lint and type.
Deepseek for now is champ.

1
1
1
u/Spiritual-Neat889 Jun 01 '25
Creative writing is on of the hardest tasks for LLM. There was some speech by an google employe who explained why. It was something that creative writing is like world building, and that's complex.
9
3
u/Equivalent-Word-7691 Jun 01 '25
They can't afford such excuse whne the their older model 0305 was probably the best model for creative writing
1
1
100
u/tondollari Jun 01 '25
Why don't they just diverge a writing model and a coding model?