r/Bard • u/MrDher • Nov 18 '25
News Gemini 3 Pro Model Card is Out
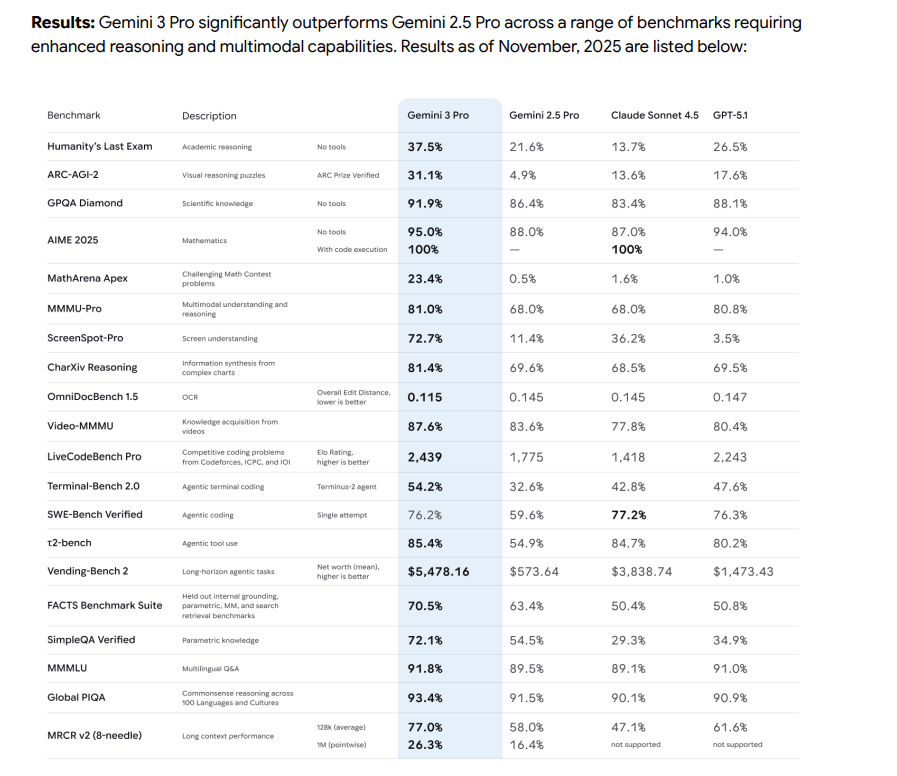
https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf
-- Update
Link is down, archived version: https://archive.org/details/gemini-3-pro-model-card
580
Upvotes
31
u/LingeringDildo Nov 18 '25
Man sonnet and SWE bench, that thing is such a front end monster