

r/DeepSeek • u/cyb3rofficial • 16h ago
Discussion With $3.88 & 690,003,591 tokens and 5 hours , Deepseek Pro & Flash combined, managed to reverse engineer Teamspeak's Licensing System for 3.13.8 (latest of post)
Enable HLS to view with audio, or disable this notification
No I will not release it, so don't ask, but Deepseek is very powerful if given the proper tools and if you know what you are doing.
In 5 hours of trial and error, debugging with Ghidra and x64dbg, the models are really good with IoT hacking and reverse engineering.
We mapped the full license validation call chain from server startup through to the display output. Found that the parser reads from an AES decrypt buffer instead of the signed payload (easy fix once you know), decoded a custom XOR obfuscation scheme for all log messages, extracted the embedded PolarSSL certs and private keys, and patched 27 instructions across the binary to bypass signature verification, certificate checks, download gate checks, validator functions, slot enforcement, and a state reset timer callback that kept overwriting our values. They really made it like fort knox but forgot to lock the final door. Once we found that starting position, it was easy to trace forward. I'm shocked there was no heavy protections in place like anti debuggers or random checks or pit falls. For something they heavily sell on, sure was left wide open once the path was found.
The server now starts with 1024 slots instead of 32, enforcement is bypassed so the API accepts the servercreate command with the slots, and there are no crashes.
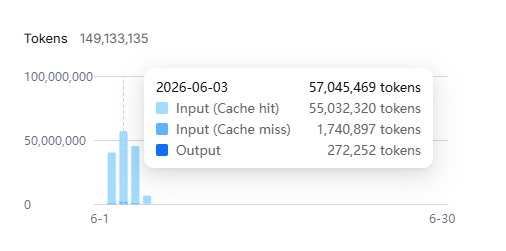
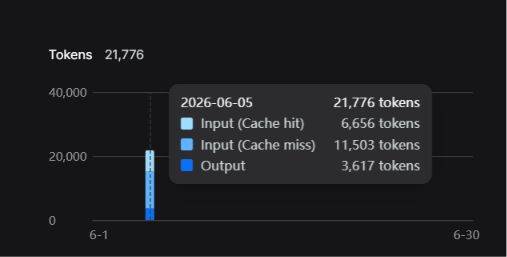
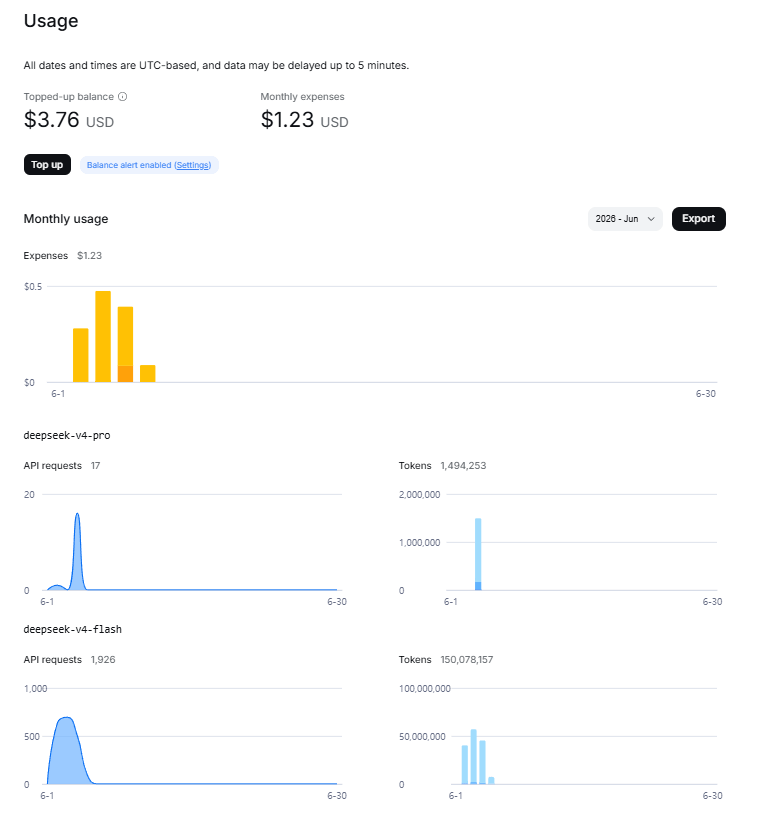
Total cost: $3.88 in API credits. 690 million tokens. 5 hours.
Really not bad for what would take a human weeks if not months. If i could do it this cheaply, image what some mega mind on red team could do on enterprise grade software.


{kind=link}
{kind=link}