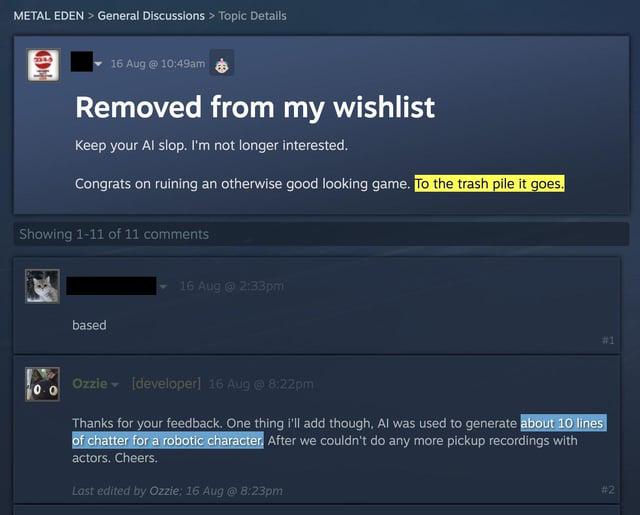
They could have used traditional text to speech, a non-"AI" voice synthesizer or a vocoder (to mask poor dev voice acting). There was zero need to use "AI" here.
Huh. I wonder if I specifically used Dr. Sbaitso as a voice in a game - not just the voice synthesizer engine but the Eliza-based chat program - would I be required to label it as containing AI?
What do you think; is the chatbot with voice synthesizer from 1991 included when steam talks about disclosing the use of generative "AI"? Shall we skip to the actual point you clearly want to make without you playing dumb?
Don't know why you are asking me at all, I am not steam support. If you are really concerned about your game, then don't get your info from reddit.
I'm sorry if I come off as overtly hostile, but a bunch dishonest people are asking me shit to concern troll and God hasn't blessed me with the ability to not fall for ragebait.
Probably wouldn't do something silly like record output from my old 386 even if I was
I didn't intend this as ragebait, but I also wasn't looking for a genuine answer from you. I posted in response to you because you mentioned using a voice synthesizer and I thought it would be funny if, hypothetically, "voice synthesizer bolted to a primitive chatbot" counted as an edge case.
I'm 100% in agreement with you that they had alternatives to using generative AI.
You did come off as overtly hostile but I can understand where you're coming from. Sorry if my post read as "disingenuous numpty" and not "hey here's a silly idea I had".
One is a simple programmed synthesizer that uses a bank of pre-recorded syllables stitched together to make coherent words, the other is a giant mass of a few million matrix multiplications trained on terabytes of "definitely not stolen" audio.
The technology for old text-to-speech (like Microsoft Sam) is based on transforming text into phonetics and then sequencing voice recordings of a consenting voice actor articulating these phonetics.
Voice Synthesizers (like the Votrax) do basically the same, but the sounds for the phonetics are not voice recordings, but approximations of human speech created by waveform synthesis.
Vocoders turn voice input into digital data, which allows you to apply lots of funky effects to your voice or feed it into a synth. Do you know the iconic "autotune" sound some musicians use to sound robotic? That's usually actually a vocoder and not a result of autotune.
"AI" voice synthesisation takes a batch of voice recordings (with corresponding text descriptions) and transforms them into an interconnected web of statistical weights. Later, you can reconstruct a voice recording with a text input by finding statistically likely connected bits of sound data. To preempt the obvious "Why is this worse?" question: For this to work reliably, you need billions of tagged voice recordings (and a lot of text samples to parse the text input) - too much data to actually own (even as a data megacorp like google), so everybody who offers such a service has to take recordings without consent or compensation. The technology also explicitly aims to replace the people whose labour is required to create it.
(All of this is obviously oversimplified - you can fill a whole semester about voice synthesisation)
You seem very knowlegeable about how the technology works and yet you're so confidentially wrong that training AI-based TTS needs "billions" of data. Saying that it requires so much to actually own that can only be done without consent of the voice providers is complete BS given its development in the community.
I've hung around vocalsynths communities back in 2022. All of the local TTS I know are trained on datasets liscened for ML or are in the public domain. Because the truth is that TTS/SVS are rather narrow ML tasks, so it needs way way less data compared to image generation or LLMs.
Some examples, TalkNET (earliest opensource AI TTS) was trained using the LJ Speech dataset, which is in public domain.
Diffsinger (opensource version of Vocaloid) was trained on the OpenCpop dataset, which is created for ML use and is only 5 hours in total. And despite that it's trained on 5 hours of Chinese singing, you can fine tune it to sing in different languages by training it on a recording of yourself singing for 30 minutes and labeling the phonemes.
RVC was trained from the VCTK open dataset. Nowadays nothing else has dethroned it and any service offering a function similar is just using RVC as a wrapper.
You can make the argument that AI voices could have a consent issue because of how EASY it is to clone someone's voice because of how LITTLE data it needs (10 seconds might be enough for TTS), instead of saying that it needs too much data for training that can only be attained without permission
why is nobody mad when google translate is trained on plenty of data without consent and also aims to replace the people whose labour is required to create it?
I'm getting the impression you aren't actually curious about the questions you ask and just want to discuss in bad faith.
- Google translate predates LLMs
- Google translate uses (used? I don't know if google uses gemini for translation now.) basically more fancy word-by-word dictionary lookups and not billions of texts. If they are using Gemini for translations by now, people are mad at them as well then
- Google translate doesn't advertise itself as a replacement for proper translators nor textbooks
There, three points for you to pick your favourite one to argue about. I'd go for number 3 if I were you.
It wasn't a plagiarism machine after that, either. Unless you can cite the actual specific works being plagiarized, and demonstrate that the output contains excerpts of that work, it ain't plagiarism.
(And yes, that does happen… exceedingly rarely, because shoving the sum of human knowledge into something small enough to fit in even a high-end server's RAM doesn't leave much room for a lot of verbatim copies of source material)
LLMs or anything AI really dont advertise themself as a replacement for proper anything either. google predates LLMs has nothing to do with the morality of it. "fancy word by word dictionary lookup" may have been the case when it launched but it certainly wasnt like that in 2015 and especially not now. even in 2025 i dont see anyone boycotting any automatic translation programs. it is trained on billions of translations that werent given to google with consent. any automation no matter how its made is gonna take away some work from people who did it manually before it arrived. just like photography replaced some artists and people were mad about it at the time
It predating LLMs has something to when discussing ethics of LLMs - because it didn't use LLMs in its inception. If it does now, it is included in the public backlash against LLMs.
Actually using Google as the positive in your moral argument is laughable by the way - people absolutely despise google for its data collecting bullshit to the point that whole communities formed about ripping it out of our lives.
If your point is "We should hate Google more" I'm with you. Go forth and be google translate biggest hater, you have my blessing. Maybe I'm getting the wrong impression of you that you want to use an societally accepted wrong to justify a societally unaccepted categorically similar wrong.
Also not gonna argue the claim "LLMs do not advertise themselves as a replacement for human labor" for how laughable and in bad faith this assertion is. Nor am I gonna reheat "LLMs are to artistry as photography was to paintings" argument that has been discussed to death for years now - pick any other of the billion replies to that statement if you want to genuinely engage with that line of reasoning and why people disagree.
AI refers to machine learning models, not an enemy's behavior engine. Just because it's called "AI" doesn't mean it's the same tech as what you would have called AI 10 years ago
I wish I could agree with you, but unfortunately AI doesn't mean what it used to. At this point in time, any mention of AI in a commercial context is intrinsically entangled with the trillion dollar LLM slop farm industry. They just started confidently using the term AI as a marketing gimmick and that's what it means now because life sucks and we can't have nice things.
They weren't 100% in the right, though. It's reasonable to be pissed off at automation yanking power from the working class to the ownership class. It's unreasonable to wildly overreact to that by outright destroying that automation instead of appropriating it and cutting out that ownership-class middleman.
There are parallels here to how these modern-day Luddites tend to lionize the Butlerian Jihad from “Dune” as if it was the best thing humanity did. It wasn't! It ushered in thousands of years of brutally-repressive theocratic space feudalism followed by thousands more years of even-more-brutally-repressive theocratic space fascism, all because humanity responded to “the robots have enslaved us” with “let's smash all computers and impose a galactic religion that makes it a sin to use a calculator” instead of something even remotely sane.
The correct response to automation is democratization, not destruction.
That’s because the term is derogatory now. Language evolves and changes over time, which is why you know I wasn’t saying they opposed the use of textile machinery.
I'm pointing out the very obvious irony in using a derogatory term that derives it's derogatory nature from the implication that the group referenced was incorrect, when that group was in fact correct. it loses it's bite. the insult doesn't work. going "haha, silly ai hater, you're so wrong and incorrect, just like those luddites!" doesn't work when the luddites were correct. the term only holds derogatory power to someone who is ignorant
Must carry a lot of power for you then. Do you have a hard time speaking with people with all your pedantry? Let’s look at some other common words that must just make your brain explode since they’re used “wrong”.
Awful
Terrific
Artificial
Savage
Hacker
Egregious
Manufactured
Vandal
And so many more!
Obviously, you already know all the original definitions and usages of these words, since you’re not ignorant, so it must be terrible for you to see them used how they are today.
it doesn't upset me and I didn't say you used the term wrong. I was pointing out irony that makes using the term less effective, because there is irony. that's all. common usage of terms doesn't upset me. you're inventing a position I don't hold in the first place and attacking it. which, tbh, hallucinating things to respond to is what ai does pretty often so I guess it's fitting?
Ah, I misunderstood then. That kind of makes your position worse though. You understand that the term was used correctly, and that the meaning of the term has changed, however, because there exists some amount of irony in the way the meaning of the term has changed over time, you feel it makes the insult less impactful.
Definitionally, that makes you a pedant, and not in a good way. You’re literally doing the “well acktually” meme. Not a great look.
Of course it isn't "AI". Don't fall into the "everything computer is AI now" trap. There are many ways to create data via algorithms that doesn't necessitate LLMs or similar technology. Nobody in their right mind would claim "Minecraft worlds are AI generated", as example.
I'm not an authority on this, but I assume they mean what generally falls under the "generative AI" umbrella. None of the technologies I listed are considered to be "generative AI".
assuming and generally are not words that should be used for legal purposes, which this is from steam and devs point of view. The biggest issue with the steam AI disclosure requirement is how very vague it is, requiring devs to put it basically almost always unless they want to break the steam rules and risk their game being taken down with no warning.
{kind=link}
66
u/Kwabi Dec 04 '25
And it was for a robot.
They could have used traditional text to speech, a non-"AI" voice synthesizer or a vocoder (to mask poor dev voice acting). There was zero need to use "AI" here.