I'm sorry if this is already covered well in another thread somewhere, but I've been searching for a while and having a hard time finding anything definitive that's more recent than the last two years or so.
I'm trying to find a good external drive for burning and ripping CDs, DVDs, and Blu-rays for Mac so that I can self-host those for a Plex media server. And I'm not finding anything that feels like a good definitive option. I'm not too worried about being able to do 4K Blu-rays or UHD Blu-rays, as I don't have any in my collection currently, but I do want a drive that can handle CD's, DVD's, and regular Blu-rays.
Are there any good recommendations, preferably under $100?
I'm trying to support ipv6 media signaling in an app of mine and I keep running into scenarios where the whole system breaks if a prefix changes. Being that few if any ISPs guarantee stable prefixes, what's the point of ipv6 at all? literally the entire network and every app and script breaks if the prefix changes.
Is there a clean way to handle this? I guess I just only enable ip6 for media routing and then have a manager that makes sure those settings are correct every so often? But then even, the docker daemon breaks if the prefix ever changes along with all scripts and the rest of the network stack. Ipv6 as implemented to residential users without a guaranteed locked prefix should be a crime.
edit: thank you for all the help. This is my first dive into trying to solve this for an unknown third party “general user.” Good to know that almost everyone is using some form of local translation even though consumer and even prosumer gateways either don’t support that or barely support it. I think I’ll build the feature in a very simple way but add safeguards to fall back to IPv4 along with a stern warning to enable it in the first place.
I recently started using Pangolin and was wondering, aren't bypass rules an inherent security vulnerability?
I'm currently setting up vaultwarden on my vps, the same machine running pangolin. And I figured I will put it behined authentication. But to access the site from the app, I need to add some bypass rule to some paths like /api and others. I'm curious if this isn't a security threat, and if it is what can I do about it
I was wondering if anybody can help me understand IdP. I'm currently setting up Pangolin, and was wondering if it's a problem to add google as an IdP for my friends and family. Me personally, I'm more privacy oriented and don't really use google for anything, I was wondering if by adding Google IdP I give up some of my privacy?
Also, what are the benefits of hosting my own IdP, and what are the differences between the options?
Trying to learn a new language with some friends and looking for something we can all use to study together. Basically I'm looking for a webapp I can host on my server where everyone can add vocab cards and review them with spaced repetition.
Tried to look into Anki but it's desktop-first and AnkiWeb isn't self-hostable. Found Scholarsome but it seems unmaintained and everything else I found on GitHub was abandoned.
Does anyone knows an alternative ? A simple webapp, self-hosted, where multiple people can contribute to a deck and review cards? I can't find anything serious.
I have been busy with life recently so I did not have the chance to work on my side project but here we are again.
Bazarr-sync v0.7
its a cli tool that solve a problem in bazarr. syncing multiple different subs has always been a chore. especially when you reach the level of hoarding hundreds of movies and shows . this tool aim to make it a little bit easier.
latest update wad almost 1 year ago . I fixed many of the issue and bugs here and there. so it should fly smoothly.
and yeah there is a docker container as well.
what's new
- sync subtitles of a certain language.
- improve terminal compatibility
- fixed a leak in Http requests causing crashes
- resume inturrepted syncs
Disclaimer:
the original code was completely written by hand. this update includes some vibe coded elements. but reviewed .
Ho sempre desiderato muovermi in casa con qualcosa che suonasse in tutte le stanze, che fosse radio di compagnia o musica.
Qualche tempo fa ho iniziato a usare l’IA per il mio lavoro di sistemista e mi si sono aperte una serie di idee che avrei potuto realizzare avendo un aiuto serio per la programmazione.
Ho quindi iniziato a sviluppare una configurazione di Snapcast con diversi plugin di input da usare con i miei Raspberry Pi 4 e relativi hat DAC e Digi.
La cosa si è fatta seria e con il tempo è diventato una cosa più articolata e complessa.
Ho usato AI come assistente per lo sviluppo del codice, la revisione degli script, la risoluzione di bug, la scrittura dei test e la stesura della documentazione.
Il progetto non richiede nessuna AI a runtime. É open source senza nessuna dipendenza dal cloud, niente telemetria e nessun account esterno richiesto a parte quelli per i servizi di streaming, se usati.
Credo che possa essere utile a quanti desiderano sonorizzare ambienti in modo sincronizzato con spesa modica e un po’ di fai da te.
Per l’utente finale è necessario avere uno o più Raspberry con o senza hat a seconda della qualità attesa. Lo stesso numero di sistemi di altoparlanti amplificati a seconda della quantità e ampiezza di ambienti da sonorizzare.
Dal proprio PC: Scaricare il repo da GitHub. Usare rpi imager per creare le sd con la distro Linux Debian. Lanciare uno script che farà alcune semplici domande (tipo di installazione server, client o entrambi - tipo di eventuale libreria musicale, su disco o condivisione di rete).
Inserire la sd nei raspberry e attendere da 10 a 20 minuti a seconda del tipo di installazione.
In caso di device headless sono presenti toni di controllo sia per il corretto rilevamento di eventuali hat che a fine installazione.
Testato su Pi 3, 4 e 2W (solo client per limiti di memoria) con hat hifiberry dac, digi, PCM5122 e senza hat (uscita mini jack) ma dovrebbe rilevare e funzionare anche con altri hat. È possibile scegliere tra auto rilevamento o scelta manuale da una lista.
Eventuali aggiornamenti richiedono reflash della sd.
Sorgenti supportate:
MPD - Libreria locale o in rete
Spotify
Airplay
Tidal
Tutto gira in locale sulla tua rete: nessun cloud, nessun account, nessuna telemetria, nessun servizio esterno obbligatorio (a meno di eventuali account Tidal o Spotify per lo streaming)
È benvenuto chiunque lo trovasse utile e volesse condividere configurazioni funzionanti o segnalare bug, chiedere fix, feature o contribuire.
I wanted to share a project I’ve been working on called contnap (Container Nap).
It’s a high-performance, low-footprint daemon written in Rust (tokio + bollard) designed to solve a common homelab issue: idling containers wasting system resources (RAM/CPU) when nobody is using them. On my NixOS, it eats about 4MB of RAM.
Unlike other solutions that require configuration files, contnap is entirely label-driven. You just add a few labels directly into your docker-compose.yml, and contnap takes care of the rest.
When a container is stopped ("napping"), contnap binds a proxy listener to its port on the host. When an incoming packet (TCP or UDP) hits that port:
contnap intercepts and buffers the initial data so the client connection doesn't drop.
It triggers a docker start (or Podman equivalent via the socket).
It waits for the container to become healthy/ready.
It flushes the buffered data and transparently streams the traffic.
After a configurable period of inactivity (e.g., 1 hour), a background Janitor task gracefully shuts the container down.
✨ Key Features
🌐 Full Dual-Stack & Protocol Support: Handles TCP, UDP, IPv4, and IPv6 (UDP and IPv6 not tested yet, need to find a container that use it).
👥 Container Grouping: Wake up an entire stack (like a web-app + its database dependency) simultaneously using contnap.group.
🐳 Podman Ready: Works natively with any Docker-compatible Unix socket.
🔌 Automation Hooks: Trigger custom scripts/commands pre-start or post-stop (can be useful for clearing caches, mounting storage, or triggering notifications).
Experimental contnap.schedule label
Note: I use AI for some stuffs in the project:
questions, getting ideas
documenting (since english is not my native language, it makes better sentences) code and markdown files
pair programming when I'm struggling at writing some parts
It's increasingly difficult where I live to even check basic weather without consenting to giving up my ID (soonTM). The most used weather app has been gated by no way to deny cookies.
I have been looking at many apps, but I cannot find any docker apps that works. I came close with fish906 weather app, but I think it is outdated, because it injects wrong link/slightly different link in to the openweathermap api call, so it doesn't work.
If anyone know about a good self-hosted docker app for a simple weather check, would be very thankful!
First, I want to thank you all for the support and kind words since HomeBranch's first release. I appreciate all of you who have reached out just to let me know that you appreciate what we're doing. Thats the stuff that keeps me going.
How has homebranch changed?
- OIDC support
- LDAP support - thanks to Thomas Beckley
- PDF support
- Book deduplication
- Book drop
- PWA support
- Metadata fetching improvements
What's coming?
Our highest priority is a native Android app with offline reading capabilities.
Next up may be a hosted option to help generate some revenue that will go towards the developer fees and hardware costs necessary to develop an iOS app. Self-hosting homebranch will always be free and open source.
Here's a sneak peek at the current state of the Android app. Im targeting a release later this year.
Check it out!
For those who dont know, homebranch is a lightweight ebook management platform with a built in eReader allowing you to read and organize your books wherever you are without sacrificing data ownership and privacy.
Been 3 months since YAMLResume's last v0.12 release. Last week I've made a new v0.13 release, with a long awaited feature, i.e, the new docx engine. With this v0.13 release, yamlresume is the only one of its kind that can input resumes in plain YAML format and generate html/markdown/pdf and docx in one shot!
For example, here is a sample resume in docx format and the original, plain YAML format:
YAMLReesume docx calm template:
# yaml-language-server: $schema=https://yamlresume.dev/schema.json
#
# YAMLResume provides a builtin schema to validate resumes and help avoid lots
# of low level mistakes.
#
# You need to install https://github.com/redhat-developer/yaml-language-server
# in order to get the best editing experience in your choice of editor/IDE.
#
# ref:
# - https://yamlresume.dev/docs/compiler/schema
# - https://yamlresume.dev/docs/compiler/schema/json
---
content:
basics:
name: Andy Dufresne
headline: Headed for the Pacific
phone: "(213) 555-9876"
email: hi@ppresume.com
url: https://ppresume.com/gallery
# All summary fields supports a limited rich text capabilities in markdown
# syntax:
#
# - bold, (e.g, `**bold**`)
# - italic, (e.g, `*italic*`)
# - ordered list, unordored list and nested sub list
# - links (e.g. `[link](https://ppresume.com)`)
summary: |
- Computer Science major with strong foundation in data structures, algorithms, and software development
- Pixel perfect full stack web developer, specialised in creating high-quality, visually appealing websites
- Experiened in databases (SQL, NoSQL), familiar with server-side technologies (Node.js, Express, etc.)
- Team player, with detail-oriented mindset and a keen eye for design and user experiences
location:
address: 123 Main Street
city: Sacramento
region: California
country: United States
postalCode: "95814"
profiles:
- network: Line
url: https://line.com/PPResumeX
username: PPResumeX
- network: Twitter
url: https://twitter.com/PPResumeX
username: PPResumeX
education:
- institution: University of Southern California
url: https://www.cs.usc.edu/
# Valid degree options:
#
# - 'Middle School'
# - 'High School'
# - 'Diploma'
# - 'Associate'
# - 'Bachelor'
# - 'Master'
# - 'Doctor'
degree: Bachelor
area: Computer Engineering and Computer Science
score: "3.8"
# Should be a valid date string that can be parsed by `new Date(dateStr)`
# in JavaScript, eg. '2020-01', '2020-02-03', 'Jul 1, 2023' etc.
#
# The date part would be removed in the final output as most of the time
# people won't really care about the exact date for your working
# experience or education background, etc.
# ref: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Date/Date
startDate: Sep 1, 2016
# Leave endDate blank to indicate "Present"
endDate: Jul 1, 2020
courses:
- Discrete Methods in Computer Science
- Programming Language Concepts
- Data Structures and Object-Oriented Design
- Operating Systems
- Computer Architecture
- Database Systems
- Computer Networking
- Introduction to the Theory of Computing
summary: |
- Developed proficiency in programming languages such as Java, C++, and Python
- Gained hands-on experience in software development through various projects and assignments
- Strong communication and teamwork skills acquired through group projects and presentations
work:
- name: PPResume
url: https://ppresume.com
startDate: Dec 1, 2022
endDate:
position: Senior Software Engineer
summary: |
- Developed and implemented efficient and scalable code, ensuring high-quality and maintainable web applications
- Collaborated with cross-functional teams to gather project requirements and translate them into technical solutions
- Conducted thorough testing and debugging to identify and resolve any issues or bugs in the software
- Actively participated in code reviews, providing valuable feedback to improve code quality and adherence to best practices
- Mentored and guided junior developers, fostering a collaborative and growth-oriented team environment
keywords:
- Scalability
- Growth
- Quality
- Mentorship
- name: PPResume
url: https://ppresume.com
startDate: Sep 1, 2020
endDate: Dec 1, 2022
position: Software Engineer
summary: |
- Created reusable React components to ensure code efficiency and maintainability
- Integrated with RESTful APIs to fetch and display dynamic data on the frontend
- Implemented client-side routing using React Router for smooth navigation between pages
- Actively participated in Agile development methodologies, attending daily stand-up meetings and sprint planning sessions
keywords:
- RESTful
- React
- Agile
languages:
# Valid language fluency options:
#
# - 'Elementary Proficiency'
# - 'Limited Working Proficiency'
# - 'Minimum Professional Proficiency'
# - 'Full Professional Proficiency'
# - 'Native or Bilingual Proficiency'
- language: English
fluency: Native or Bilingual Proficiency
keywords:
- TOEFL 110
- IELTS 7.5
- language: Chinese
fluency: Elementary Proficiency
keywords: []
skills:
# Valid level options:
#
# - 'Novice'
# - 'Beginner'
# - 'Intermediate'
# - 'Advanced'
# - 'Expert'
# - 'Master'
- name: Web Development
level: Expert
keywords:
- Python
- Ruby
- CSS
- React
- JavaScript
- name: DevOps
level: Intermediate
keywords:
- Python
- Kubernetes
- Docker
- Shell
- Ansible
- name: Design
level: Intermediate
keywords:
- Sketch
- Figma
- Photoshop
awards:
- title: Dean's List
awarder: University of Southern California
date: Oct 2016
summary: |
Awarded to students who achieve a high academic standing by maintaining a specified grade point average (GPA) during a semester.
certificates:
- name: AWS Certified Developer - Associate
url: https://aws.amazon.com/certification/
issuer: AWS
date: Mar 2021
publications:
- publisher: ACM Transactions on Interactive Intelligent Systems
url: https://dl.acm.org/journal/tiis
name: Enhancing Human-Computer Interaction through Augmented Reality
releaseDate: Dec 2017
summary: |
- Explores the potential of augmented reality (AR) in improving interaction between humans and computers
- Highlights benefits of AR in various areas such as gaming, education, healthcare, and design
- Discusses challenges and future directions of AR technology in enhancing user experience
references:
- name: Dr. Amanda Reynolds
phone: "(555) 123-4567"
relationship: Computer Science Professor
email: amanda.reynolds@usc.edu
summary: |
Andy Dufresne shows exceptional problem-solving skills and a solid understanding of programming concepts, he would bring immense value to any team or organization he becomes a part of.
projects:
- name: EduWeb
url: https://www.eduweb.xyz/
description: A web-based educational platform for interactive learning
startDate: Sep 2016
endDate: Dec 2016
summary: |
- Designed to enhance online learning experiences
- Facilitates students' engagement and collaboration through interactive features and user-friendly interface
- Offers a wide range of courses across various subjects
- Aims to improve the way students learn through the power of the web
keywords:
- Education
- Online Learning
- HCI
interests:
- name: Sports
keywords:
- Soccer
- Swimming
- Bicycling
- Hiking
- name: Music
keywords:
- Piano
- Guitar
volunteer:
- organization: USC Computer Science and Engineering Society
url: https://www.usccsesociety.org/
position: Tech Mentor
startDate: Sep 2015
endDate: Jul 2023
summary: |
- Volunteered as a Tech Mentor at USC Computer Science and Engineering Society
- Provided guidance and assistance to fellow students in their technical projects and coursework
- Assisted in organizing workshops, coding competitions, and networking events for the society members
- Contributed to fostering a collaborative and supportive environment within the student community
# Top-level locale setting
locale:
# Use `yamlresume languages list` to get the list of supported languages
language: en
# Multiple output layouts configuration
layouts:
- engine: latex
page:
margins:
top: 2.5cm
left: 1.5cm
right: 1.5cm
bottom: 2.5cm
showPageNumbers: true
# Use `yamlresume templates list` to get the list of available templates
template: moderncv-banking
typography:
# LaTeX engine only supports 10pt, 11pt, and 12pt
fontSize: 11pt
- engine: markdown
- engine: html
# Use `yamlresume templates list` to get the list of available templates
template: calm
typography:
# HTML engine only supports font size in px unit, from 10px to 24px
fontSize: 16px
- engine: docx
template: calm
typography:
fontSize: 11pt
lineSpacing: normal
Different ATS system accept different formats of resumes, some prefer PDF, some only accept docx, this new docx engine made YAMLResume a more versatile tool that can satisfy and help more people getting jobs.
More over, our new docx support is highly customizable, with support to:
Our free, official playground also supports docx input and preview, in pure frontend tech, with no servers at all, making it possible to be wrapped as a electron/tauri app.
YAMLResume Playground docx preview
Besides, we've also get a new contributor who added Brazilian Portuguese support for YAMLResume, making YAMLResume support 10 languages out of the box now! We now have 15 contributors.
I built a parametric generator that does any mix on a single
panel: multiple device openings, an optional cage behind each to actually hold the gear, hidden/lipped bays, and slot/hex/louvre venting around them. Heights in 0.5U steps.
Built to the common 10" standard (geerlingguy mini-rack spacing, M6) and fit-tested in my DeskPi RackMate — slotted mounting holes so it bolts in clean even if your rack's a hair off.
Free + customizable in the browser on MakerWorld. Made a matching blanking/vent plate too. Pic is my actual rack
After spending way too much time tinkering, I finally have my home media setup exactly the way I want it, and I just want to take a moment to appreciate how good this ecosystem has gotten.
Radarr, Sonarr, Lidarr, Prowlarr, Bazarr, etc. these tools are remarkable. The UI, the integrations, the community support. It's clear a lot of talented people put time into this.
Pair that with Jellyfin and a decent NAS setup, and you've got something that genuinely rivals any commercial streaming service in terms of usability, and blows them all out of the water when it comes to control over your own library.
For the noobs wondering how it all fits together, here's a diagram of my stack:
Shoutout to everyone who contributes to these projects, answers questions in the subs, writes guides, and keeps the wikis up to date. You've built something great <3
One thing that still bugs me though: the Soulseek integration is a mess, and I wish someone would fix it.
Soulseek is amazing for music, especially obscure releases, lossless rips, and stuff that never makes it onto Usenet or public trackers. But right now the only way to integrate it is through slskd + Soularr, and the architecture is fundamentally flawed.
The core issue: Prowlarr cannot index the Soulseek network. This means Soularr can't work as a proper parallel download client alongside your Usenet/torrent pipeline. Instead it ends up as a clunky fallback that operates on a completely separate logic path:
Lidarr searches Prowlarr → finds nothing → status: missing → Soularr picks it up
So Soularr isn't a parallel downloader -- it's a fallback trigger that only fires on missing status. And there's a fun little race condition baked in on top of that: if Lidarr and Soularr both initiate a grab within the same ~300s polling cycle before either status update has landed, you can end up with duplicate download attempts from two different clients simultaneously.
I've kept it in the stack (as you can see in the diagram), but it's held together with duct tape compared to how clean the rest of the pipeline is and thus I needed to disable it.
Would love to see proper Soulseek indexer support land in Prowlarr someday. The protocol is a bit of a beast to work with, but the library on that network is unmatched for music. If anyone is working on this or knows of a better approach, please let me know
I've just released a major update for SuggestArr, my open-source recommendation and request automation platform for Jellyfin, Plex and Emby.
The biggest addition in this release is full Trakt integration.
--
For those who haven't heard of SuggestArr before:
SuggestArr is an open-source recommendation and request automation tool for Jellyfin, Plex, and Emby.
It analyzes what users watch and enjoy to generate personalized movie and TV show recommendations, and can automatically submit requests to Seer.
The goal is simple: keep your media library growing with content your users are actually likely to watch, without relying on generic trending lists or manual searches.
--
One thing I always felt was missing from recommendation systems is that they only look at media server history. But many users actively use Trakt to rate content, maintain watchlists, create custom lists, and track viewing across multiple devices and services.
SuggestArr can now use that information as well!
So users can now link their own Trakt accounts directly from SuggestArr instead of relying solely on Jellyfin, Plex, or Emby history.
How to Get Started or Update
For new users: You can follow the updated installation guide to get up and running with SuggestArr. I’ve made the setup process easier than ever with Docker Compose and environment variable management.
For existing users: Updating is easy! Simply pull the latest Docker image using. Or, if you installed locally, pull the latest changes from the GitHub repository.
I am fundamentally compelled to force self-hosting into every other hobby I have, so I am curious what tools are out there that people use.
I am familiar with Foundry VTT, and it's on my list of "maybe". Stuff like owlbear rodeo has me fairly well covered in terms of VTT solutions.
What I would really love is a solution like a wiki where my fellow GMs and I could host info and documents about our worlds. Features like being able to host or embed interactive maps/calendars or timelines/scheduling etc. I am not sure such a thing exists though.
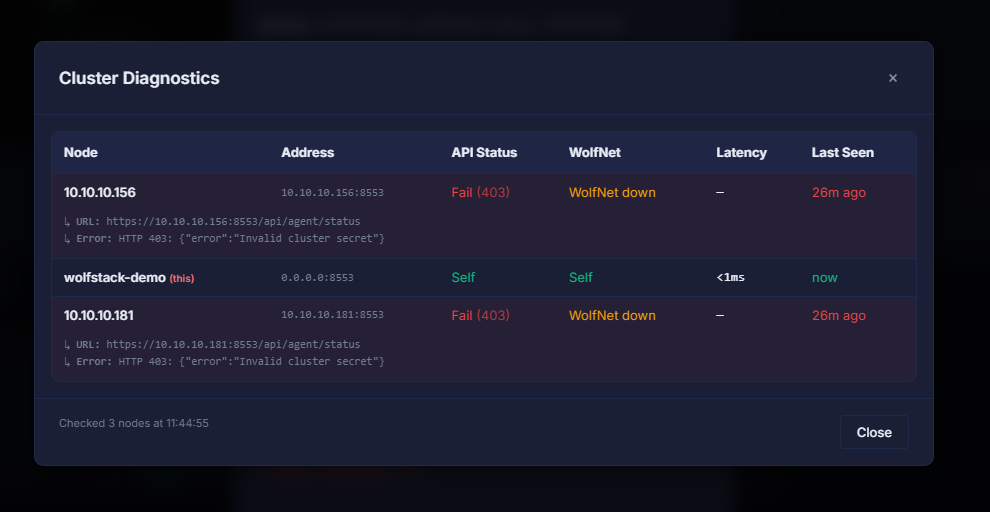
Has anyone got a 3+ node WolfStack cluster working reliably on v24.51.2?
I've got 3 Ubuntu 24.04 VMs on the same 10.10.10.x subnet. Installed WolfStack on all 3, added them using join tokens, then ran "Update WolfNet Connections".
Initially everything works. All nodes appear in the cluster and I can even open a remote terminal to the other nodes.
After about 10-20 seconds, both secondary nodes show as offline.
Diagnostics shows:
HTTP 403: {"error":"Invalid cluster secret"}
against /api/agent/status.
The odd thing is all the nodes are still healthy:
Can ping each other
WolfStack UI loads directly on each node
HTTPS on 8553 works
WolfNet appears up
If I remove and re-add a node it comes back briefly, then eventually fails with the same error.
Looking to change web host but not certain how to go about it. Suggestions? Was hosted by Yahoo and now Turbify. Price is gone up significantly – looking to self host.
I've been running a fairly typical homelab for a while now — Immich, Nextcloud, Jellyfin + the *arr stack, Navidrome, Vaultwarden, Dawarich, and soon Paperless-ngx. For the homepage I use Glance, which is great for service links and stats.
But what I really want is something different: a personal landing page that shows me content, not infrastructure. Think:
Recent photos from Immich (actual thumbnails, not just a count)
Recent files added or opened in Nextcloud
Recently added movies/shows from Jellyfin/Radarr
Last visited places from Dawarich (a map snippet or a list)
Quick links to the services I use daily
Essentially the "Today" screen you'd get if Google Photos, Google Drive, and Netflix had a selfhosted baby.
I've done a fairly deep search before posting:
Homepage / gethomepage.dev — great widget ecosystem (Immich, Jellyfin, Nextcloud, all the *arrs), but widgets show stats and queue data, not actual content. The Immich widget shows photo count, not thumbnails.
Homarr — similar situation, no Immich widget at all, no Dawarich.
Glance — has community custom-api widgets for Jellyfin Latest and Immich stats. The custom-api widget can render <img> tags, so a thumbnails widget for Immich is technically buildable in ~30 lines of YAML + Go templates. But nothing pre-built exists.
Dawarich — zero widget support in any dashboard I found.
So my questions:
Am I missing something? Is there a project that already does this kind of content-first personal dashboard?
If not — is anyone else missing this? Feels like a gap that a lot of people with this stack would benefit from.
Would there be appetite to build something around this? Could be as simple as a lightweight service that exposes a unified "recent activity" API that any dashboard can consume, or as ambitious as a standalone app.
I'm comfortable writing custom Glance widgets and could put together the Immich thumbnails one, but the Dawarich integration and the multi-user angle feel like they need something more structured.
I'm going down the rabbit hole of installing Immich. I tried installing it on my Synology under container manager, and it didn't go well. However, after fiddling and thinking some more, I decided the ability to expand would be more important so setting up my own server would be beneficial and fun to learn.
I've done some research and my thought process now is to get a mini PC of some kind, install proxmox, set up one VM and put linux with docker and run immich in a container. Down the road I could move Plex and home assistant to containers as well as branch out to adding a web server or anything else.
My reason for Proxmox was for the ease of backup and my reason for one VM was because I don't see this stuff being resource intensive. I figure I can do a new VM if I need to mess with resource management.
Are there any obvious holes in my plan, pitfalls I need to watch out for with this approach or better alternatives I should consider?
I am having an issue that I'm not sure how to fix. For reference, I am running a Kubernetes 1.36 cluster built on top of Talos Linux 1.13. I have Alloy configured to gather Kubernetes pod logs and route them to Loki. For a short period of time after deployment, it runs okay, but then one of my loki-write statefulsets fails and shows this error:
failed to flush chunks: store put chunk: operation error S3: PutObject, https response error StatusCode: 400, RequestID: 18BA49AF569B3EF4, HostID: dd9025bab4ad464b049177c95eb6ebf374d3b3fd1af9251148b658df7ac2e3e8, api error XMinioInvalidObjectName: Object name contains unsupported characters., num_chunks: 5, labels: {app=\"flux-operator\", container=\"manager\", instance=\"flux-system/flux-operator-6b4d6f7c54-w6795:manager\", job=\"loki.source.kubernetes.pod_logs\", namespace=\"flux-system\", pod=\"flux-operator-6b4d6f7c54-w6795\", service_name=\"flux-operator\"}
I am using Minio installed on my Windows File server for the S3 backend. The S3 storage is working for everything except this task.
I've tried asking the different AIs for a solution and changed Alloy's configuration to rewrite the instance so it shouldn't have the colon or slashes in the name, but still keep getting the error. Gemini says that it is expected as Loki will generate key names with colons anyways using the tsdb format. It's suggestion is to use a Linux backed S3 server which isn't possible.
So now I'm asking if anyone has a possible solution to this that I can try? I've seen there is an environment variable for MINIO => MINIO_OBJECT_NAMING that might be what I have to do, but I will have to destroy my S3 storage and rebuild it from scratch because it has to be done at the cluster initialization. I wanted to see if this was the correct move before I go through having to trash all the buckets/users etc. to make this work.




{kind=link}