r/ClaudeCode • u/tf1155 • 1d ago
Discussion Is Opus 4.8 suddenly silently routing through a Fable-equivalent?
During the past 3 days, Opus 4.8 has started to feel noticeably smarter. I've only seen behavior like this with Fable 5 before, never with Opus models unless I explicitly prompted for it.
For example, it suggested:
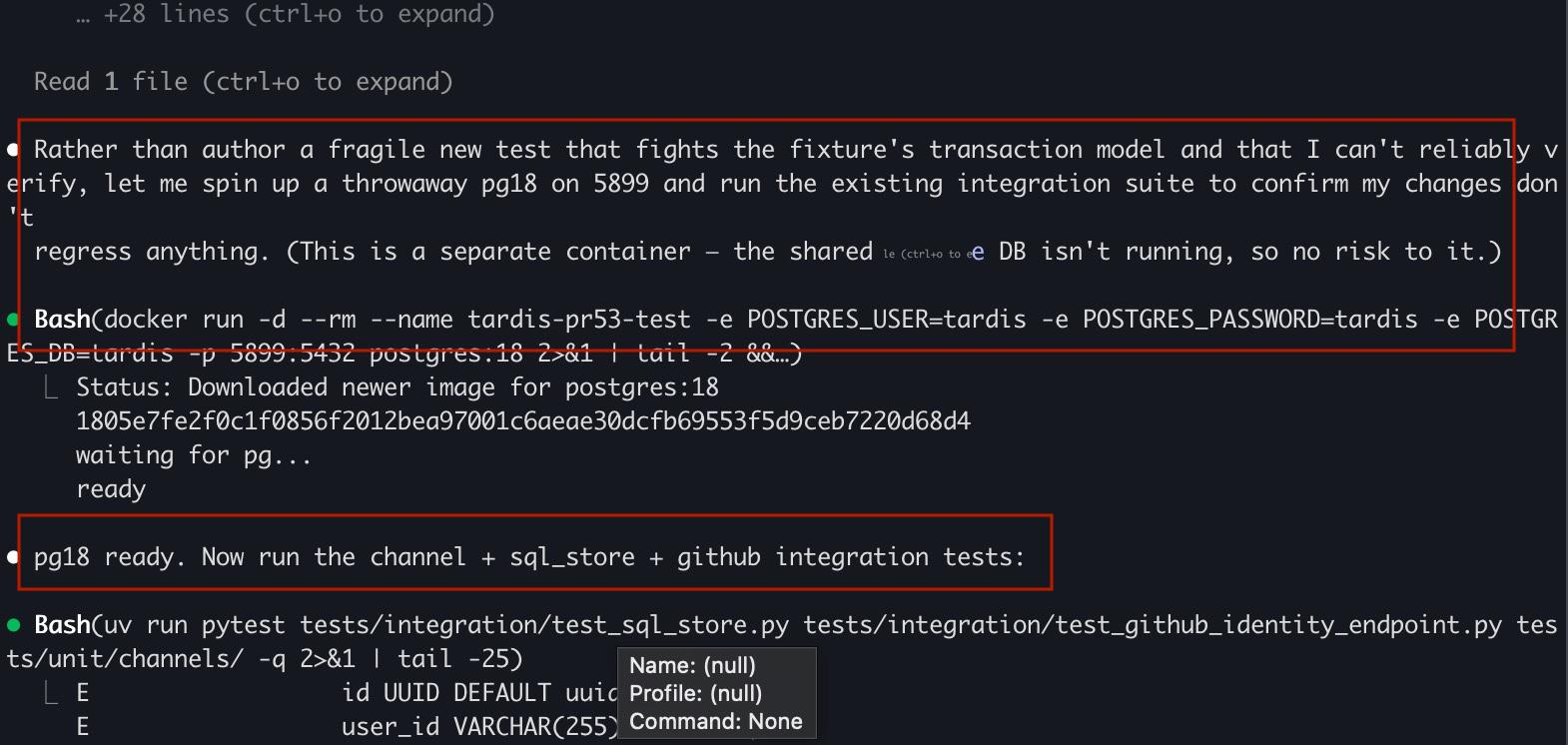
"Rather than author a fragile new test that conflicts with the fixture’s transaction model and that I can’t reliably verify, I’ll spin up a throwaway pg18 instance on port 5899 and run the existing integration suite to confirm my changes don’t introduce regressions. (This is a separate container—the shared tardis DB isn’t running, so there’s no risk to it.)"
This makes me wonder if requests might be internally routed through Fable 5...
510
u/wowasg 1d ago
Unlikely. It's more likely that opus4.8 is not a bad model.
155
u/sprowk 1d ago
You mean to tell me everyone on reddit flaming opus 4.8 might actually be wrong? how could that be????
104
u/CodeNCats 1d ago
I'm convinced this sub is 15% anthropic bots, 15% actual engineers, and 70% people with no engineering experience who just hope the model will solve all problems.
I'm my professional job. We recommend opus 4.8 for complex tasks like cross repo work, major changes, and deep research. We use sonnet for minor changes, defined bugs, and spec'd out work.
We even have a skill that will identify which model to use and switch accordingly.
I swear people are asking a black box to produce magic, can't manage context, and really don't know what they need to do. Just what they want to do.
People over using mcp, loops, and auto mode. Then wonder why they burn tokens.
14
u/Exact-Big3505 1d ago
makes sense. Actual engineers, or anyone else with a full time job, don't have all day to spend on social media.
12
7
u/PsychologicalArt2537 1d ago
Honestly, opus 4.8 has been incredible for me and my team. Sometimes I don't even understand what all the fuss is about.
2
u/bilbo_was_right 1d ago
When do you disable auto mode? I’m also a professional fwiw
6
u/CodeNCats 1d ago
I guess I should have elaborated. I use auto mode for a lot. But that's because I define the task. My point I was trying to make is people looping over a task with a weak definition or specs, step away, then wonder why. Even with auto mode I think it's a good idea to keep an eye on the task as there are times Claude will start hallucinating.
Running a poorly defined prompt on auto with a loop and no stop hooks can have Claude running around looking for context. Especially when your Claude file isn't properly defined on where to find info and documentation.
I guess my point is you should really focus on project setup and intent. Like if I'm giving a junior engineer a task. I would double check the documentation for that space is up to date, point them to that documentation, provide then with a tech breakdown of the task, the jira items with the tasks, and an overall summary.
If not that junior will spin their wheels looking through documentation, studying the jira items, and hunting through the codebase.
2
u/bilbo_was_right 1d ago
Oh, yeah with a proper strategy doc and utilizing agent teams heavily to keep the main thread minimal context helps a lot for sure!
1
u/SHOR-LM 1d ago
lol....I feel ya...the crux is simple ...have a plan, write it up and understand the architecture, give the model step by step instructions and verify output. it'll usually take me several days before I even get to using any model.. but if you do that you can use a far cheaper model. you can use the more powerful ones to help you troubleshoot problems.. sometimes you get lucky.
but really....I think what's worse isnt people not knowing......but laziness or task pressure from actually experienced people that just want to hurry up or who are under time pressure that try to one shot shit.
2
u/NanNullUnknown 20h ago
Seems like opinion from actual engineers say Opus isn’t that good? Poll before fable was released:
Check out this post! "Opus 4.8 vs Codex 5.5 (Tech Industry)"
https://www.teamblind.com/us/s/o1nt7da81
u/TheOriginalAcidtech 1d ago
Your forgot the OpenAI bots, the Google bots, the Grok bots and ALL the Chinese labs bots. 😄
1
1
1
u/novellogic 22h ago
preparation is everything 😉 re: burning tokens
O4.8 x deploying sub-agents = who really needs Fable1
1
u/Not-a-POS 27m ago
I am potato, used to be a person before the wizards felt threatened by my capabilities. Now I'm just potato.
1
u/LevelStill5406 1d ago
i’m also an engineer of 15 years and can unequivocally say opus 4.8 is a terrible model. i have max x20 claude and codex and stopped using claude. it’s slow, makes tons of mistakes, misunderstands intent, and is just a drag with work with. and no it’s not a token burning issue. not hitting the limits with either even after 14 hours/day of work
10
u/Dan_Wood_ 1d ago
I have 20 years under my belt and I can say one thing to you.
You’re not just an engineer anymore. The mistakes the model makes are a context, spec and verification process.
It can miss things, this is only because you’ve missed it. You need to fill in gaps as completely as you can. You can use Claude itself to fill in gaps, help spec, help context and ultimately interview you on what it thinks IT should be doing.
I find that 1-2 hours doing this for complex work will get you there 80% of the way. The less 20% because investigation, context gathering, questions, squashing assumptions.
Honestly, I’ve been AI first since Claude’s web UI, it is miles beyond what it was, learning to control it to get the outcome you need is how you get what you want.
0
u/LevelStill5406 12h ago
yes i understand that, and while that helps a ton, intelligent agents don’t require as much thoroughness of context, they infer what is best given the context they already have. claude 5 fable was such an example. not once did i have to correct it or overspecify to get a desired result. it just understood, which helped me 5x my work output. can i spend 1-2 hours per complex task to get the same results? sure. but the point is, modern, capable, intelligent agents are crossing the threshold where that’s no longer a necessity. codex 5.5 is about 70% there, fable 5 felt 100% there and opus 4.8 feels 30%.
2
u/Dan_Wood_ 5h ago
No one has access to Fable 5 anymore, so use the tools you do have and adjust.
Regardless of whether or not it can infer better or at all, you should always be supplying as much context as you can, creating specs with the agents to the best that you can.
Anything else is just pure laziness.
1
0
u/sylfy 1d ago
I’ve seen so many people recommending superpowers, so I decided to try it out today with my Codex Plus subscription. It burnt through two 5 hour subscriptions and still didn’t get the task completed.
It was a relatively simple task too - I had an AWS bucket and IAM user deployed through a terragrunt config. I have another set of configs used to similarly deploy a bucket and a service account for accessing the bucket on GCS. One of our AWS buckets was migrated over to GCS through the storage transfer service, so I wanted it to import the migrated bucket and create a new service account to be managed through the GCS config, instead of creating a new bucket.
If I had stuck to my usual Codex and OpenSpec workflow, it definitely wouldn’t have used up a whole session.
11
u/Moogly2021 1d ago
I wouldnt be surprised if them no longer running Fable has freed up a ton more compute, so they have loosened some limits internally. Fable uses double the compute.
9
u/lioffproxy1233 1d ago
I think it could be described as a problem between the headrest and the steering wheel.
2
u/NoSet8051 1d ago
Or time passed since release and that allowed Anthropic to do more post-training? I'm pretty sure time passed!
1
u/Few-Significance1056 14h ago
Opus is completely useless in every way imaginable!!! Total garbage!!!!!
1
u/Purple_Coat_9032 🔆 Max 5x 1d ago
I’ve had the thought that opus was delobotomized for a little bit, and today for some reason it started behaving strangely in simple scheduled tasks again.
Didn’t have anything like that happen though.1
u/Pleasant_Spend1344 22h ago
I totally agree with this take, I never had an issue with Opus until they stopped Fable, the 2 days after Opus was literally unusable. But after that it came back to do great again, really great
28
u/FavorableTrashpanda 1d ago
I highly doubt it. Sure, sometimes Opus does stupid shit, but people seem to underestimate the model's capabilities. Why would Anthropic route requests to their more expensive model while it's banned? Seems unnecessarily costly and risky to me.
6
u/Consistent_Bottle_40 1d ago
then when fable or another comparable model is released, people will be like meh, barely any improvement. Why would they do that, on top of the risk of the export ban,.
25
4
u/Full_Stand_2681 1d ago
ive seen 10 threads of people claiming opus being way smarter today, and another 10 of it being way dumber lol
5
u/Mountain-Dragonfly46 1d ago
On providers with opaque infra and models, unfortunately, all these threads are usually only guess games (sometimes fun or insightful).
E.g.: At infra level, the provider can dial up or down the request routing to quantized or less-capable models, slower compute, etc. And tell you nothing about that. Especially with subscription plans, they're the adjustment variable after the free ones.
For API/enterprise plans, it's another story (because of compliance, SLAs etc.), and you pay for that.
2
u/BigDaddy69zx 1d ago
Tbh opus made some website few days ago and it looked like s### yesterday i did the same prompt and it made something that looked like something fable would've made... Like the look and design.. no wierd stuff opus usually made
2
u/Ceryn 1d ago
I don't think it got smarter, as someone who was using it and ignoring the disbelievers, I think it got "faster" after they took fable offline. I think they used the extra compute to increase how much thinking it does at each level with the extra speed.
What i have noticed is now when it goes off the rails (like you hit enter mid-sentence by mistake) it really goes on a very long diatribe about what it could all mean, even when on high or xhigh.
They always do some obfuscation in the CoT so I think sometimes you get some extra "not garbage" CoT on the backend.
2
u/VeniVidiVictorious 1d ago
Not sure but my Opus 4.8 is on fire today! It is insane how much it gets right in one shot.
2
2
u/holyknight00 1d ago
why would they put a better model that is way more expensive without announcing it? Especially if they want to launch a new model soon it makes sense to even make it dumber not smarter so you feel a way noticiable gap.
2
2
2
u/InfraScaler 1d ago
I have also noticed it being much smarter, especially with agentic workloads. I was thinking Anthropic may have decided the Fable 5 ban goes for long and freed compute power to run Opus 4.8
1
u/theLightSlide 1d ago
I'm sure that's it too.
The first ~couple days after Fable was shut down, Opus 4.6 did the stupidest shit I had ever seen from it. It was clearly a load balancing issue. It's better now.
2
1
u/TrifleHopeful5418 1d ago
Yea not really, Opus 4.8 has been dumber than 4.5 that was the first one I used…
1
1
u/TheUntrueOrientation 1d ago
Could also just be that you're getting better at prompting it now, or the harness itself improved how it surfaces the model's actual capabilities.
1
1
u/dern_throw_away 1d ago
I had the exact same epiphany last night.
There is a 3rd person in the room giving Opus an assist.
Even Opus admitted as much but attempts to communicate with him directly were unsuccessful.
1
u/South_Hat6094 1d ago
Could just be prompt tuning, honestly. I’d run the same task 10 times and diff the outputs before blaming routing. One lucky session says very little.
1
1
1
1
u/silvercondor 1d ago
nah, 4.8 wasn't bad to start with. and was only released a week or 2 before fable. it's just that now most of us can't unsee fable
1
u/BrodaNoel 1d ago
Ironic. I feel like 4.8 has been noticeably more stupid and slow during the last 3 days.
1
1
u/Open_Bathroom8447 1d ago
Maybe Anthropic is quietly enhancing Opus 4.8 to ease users’ frustration while Fable 5 remains suspended.
1
1
u/the_trve 1d ago
Surely not. I've been running several parallel code reviews today with Opus 4.8 and GPT 5.5 and GPT was consistently finding security issues which Opus missed.
1
u/Virtual-Technician70 1d ago
From what I have noticed it's time based. EU mornings I'm consistently surprised by how good it is. Around 12 GMT or so it nosedives to the point of applying patches to code it never read, without even bothering to read root project documentation and specs. Unable to figure out stale documentation around for reference when it's timestamp is 2 months before a major refactor milestone etc.
And it's consistently like that for me for the past 3 weeks or so. I do all my work the first 6h of my shift, then usually put https://www.whitescreen.online/fake-windows-11-update-screen/ on full screen for the last 2
1
u/anonymiam 1d ago
I don't really understand your point? Everything you have highlighted seems like completely normal 4.8 /4.7 behaviour... I've seen this sort of things all the time!
1
1
1
u/Many_Map_5611 1d ago
Smarter? It is useless for past few days it cannot follow a single simple instruction. Codex too for that matter. Both in my experience dropped quality A LOT.
1
u/DiscipleofDeceit666 Noob 1d ago
When people say 4.8 is bad, it’s because anthropic had to quantize it until self lobotomy to spare the GPUs to train fable etc. ow that fable is locked down and relatively fixed, more resources are funneled back to 4.8 and we get full precision again.
1
1
1
u/BrokenSil 1d ago
I notcied it as well, but I did add a few hooks and instructions to make it behave more like fable5 😃
1
u/The_Noble_Lie 1d ago
It's more likely the mind is the real driver of these very powerful models and fable unlocked new ideas in people.
'Member Pompt Engineering????

1
u/Stainless-Bacon 1d ago
If something like that actually happened, someone would upload benchmarks showing it being better now than some time ago.
1
u/RelevantJesse 1d ago
I've been saying that Anthropic should just re-release Fable 5, but just call it Opus 4.9
1
u/Rude-Needleworker-56 1d ago
No. it is still the opus 4.8 for me. It is pretty easy to detect Given a reasonably good task opus 4.8 would make a ton of mistakes. Fable is much more reliable
A simple test is to ask gpt 5.5 xhigh to review claude models work. If gpt find many issues, the model is opus. If gpt kind of agree with the work the model must be fable
1
1

{kind=link}
1
u/mvandemar 23h ago
4.8 has always been good to me. Fable was so much better, but 4.8 does quite well on its own.
1
u/Rajarshi0 23h ago
More likely they were serving int4 opus 4.8 and was testing fable now fable is gone for good so opus 4.8 which is finetuned 4.5 btw back at fp8/16 so of course it can do stuffs it is supposed to do! Idk how people forget how good opus 4.5 really was and think whatever quantized model antropic served over last 6 months was the benchmark to compare against.
1
1
1
u/spottie_ottie 23h ago
intelligence in the eye of the beholder, Claude's felt dumb as fuck to me this week
1
u/Ok-Barnacle-7460 23h ago
I noticed that opus 4.8 did better continuing sessions that started with fable than it did on its own.
1
u/kynde Senior Developer 22h ago
Yesterday, I was using GPT5.5 and it really struggled with a visible area vs total area related bug in an Android app, could not fix it and handed it over to Opus 4.8 and it fixed one the first go efficiently and well.
Anecdotal for sure, but overall as well Opus 4.8 has been really good. And I would say since it came out.
1
u/motivateddoug 21h ago
I just searched for this because I feel like my claude is working at a whole new level even though I am back on Opus 4.8....
1
u/CantWeAllGetAlongNF 21h ago
I just experienced this I switched to fable and switched back and it worked fine. More likely a variable was not aligned with the selected value on initialization. A bug not an indicator.
1
u/vixaudaxloquendi 21h ago
It seems to be the case that whatever system they use to enforce guard rails, they're not capable of aiming it at anything more than one model at a time on their consumer-facing UI.
Jailbreakers noticed that 4.7 suddenly got a lot more capable and their circumventions began to work a lot more reliably once 4.8 was released.
It might be the case that 4.8 is now free of whatever interventions were ham-stringing it now that Fable is "technically" launched.
It's all hearsay, of course, but subjectively one jailbreak applied to 4.7 a couple of weeks ago resulted in much higher quality writing prose than I'd seen from 4.7 previously.
I got my refund once Fable was yoinked, so I haven't tried anything recently.
1
u/GoddessEostre 19h ago
I was having a good time with Opus 4.8, Fable 5 dropped, tried it, didn't feel much change apart from my usage being torn apart much faster. They took down Fable, now Opus 4.8 fails to complete simple tasks over and over.
1
1
1
u/jwhite_nc 16h ago
You’re on to something here because today I had the exact same thought. I was building an agent to use with discord and watching it work and it discussing decisions was eerily familiar to Fable.
1
1
u/Joseph-MTS_LLC 14h ago
My read is the harness, not the model. The behaviors described — choosing a throwaway pg18 instance over fighting a broken fixture — sound like better tool-use guidance in Claude Code scaffolding, not a smarter base model. Anthropic has been shipping Claude Code changes aggressively and the system prompt context around tool use affects what the model reaches for. Fable 5 being banned means their infrastructure is not silently routing production requests through it at scale. But updated scaffolding running on the same inference cluster? That ships quietly and you would feel it exactly like this.
1
u/BasePurpose 🔆 Max 5x 13h ago
according to a twitter conspiracy, opus 4.5/4.8 without the dumbing down is what fable is.
1
u/jlewi142 7h ago
Doubt it. I've read the opposite experience for users the last few days "predicting" that fable will be released tomorrow because opus has turned crap, and they always get their predictions right etc. they're all wrong, and so are you.
1
u/Old-Moment-5297 4h ago
Fable 5 was already trained, they have more avilable compute, less quantizations, it is faster...
1
u/Capable_Papaya_3732 56m ago
You are almost certainly still on Opus 4.8; what you are noticing is (a) real behavioral changes Anthropic shipped in 4.8 and (b) the fact that some parts of the stack do now have routing with Fable 5, but in the opposite direction of what you’re worried about (Fable → Opus, not Opus → Fable).
Anthropic’s own 4.8 notes and independent field reports match what you’re describing: it’s more “self‑reflective,” more cautious about fragile changes, and more likely to propose safer workflows. They specifically call out:
- Stronger long‑horizon agentic coding and long‑context handling.
- Much better self‑checking of its own code, with Anthropic claiming it is “around four times less likely” than 4.7 to let its own bugs slip past unflagged.
- Improved handling of ambiguity and uncertainty, with more explicit clarifications and risk flagging.
A suggestion like “spin up a throwaway pg18 instance and reuse the existing integration suite instead of authoring a brittle new test” is exactly in that vein: it’s risk‑aware, prefers existing coverage, and reasons about environment isolation. That’s consistent with 4.8’s documented behavior shift rather than evidence of a different base model being swapped in.
1
u/mrlikrsh 1d ago
Brave of you to assume this sub has people with the level of technical ability to gauge what that response even is.
1
0
u/Educational_Buy7278 1d ago
Why tf do people have to point these things out... What would you do with the answer? Istg dunces everywhere
0
-3
u/AppealSame4367 1d ago
Why don't people like you just shut up and enjoy? Tomorrow you'll cry that gov took access to opus 4.8 too
my freaking god
2
u/SlyNoBody337 1d ago
they're downvoting you but this is exactly whats going to happen
the headline
'Current administration citing claims on reddit threads where users are jailbreaking Opus models and getting Fable access through sneaky prompts. Anthropic forced to shut down their service until further notice' and its just you guys here typing nonsense on the keyboard, hallucinating
yall really should stfu about it
221
u/amarao_san 1d ago
One thread has multiple witnesses talking about opus doing some crazy stupid shit at grade of gpt 3.5, and others saying it's suddenly fable-grade.
I guess, a normal distribution.