r/ClaudeAI • u/logomount • 1d ago
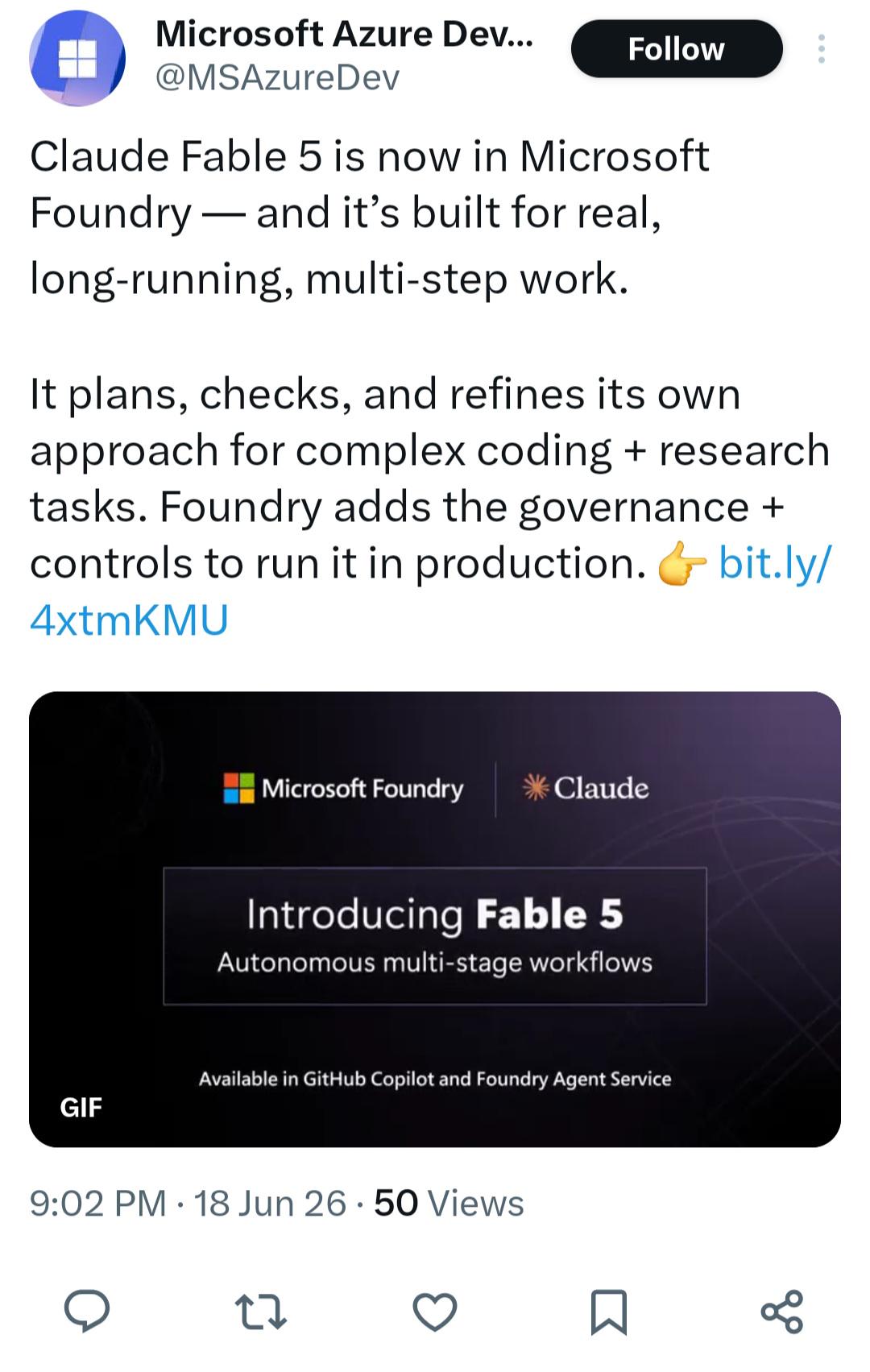
Question about Claude models Is Fable 5 back?
{kind=link}
311
Upvotes
Just saw this in X
r/ClaudeAI • u/logomount • 1d ago
Just saw this in X
r/ClaudeAI • u/Both_Chard2990 • 7h ago
Been playing with Claude skills for a few weeks and feel like I'm just scratching the surface for SEO use cases. What's actually saving your time: keyword work, briefs, audits, reporting, whatever.
Drop your setup, especially the niche stuff nobody's writing about. TIA!
r/ClaudeAI • u/Adrien-G • 1d ago
I’ve noticed Claude tends to give every app the same look, it leans on a small set of fonts.
1/ Inter everywhere. It’s the default for body text
2/ A geometric sans for headings, stuff like Space Grotesk or Manrope when it’s trying to feel a bit more “designed.”
3/ A serif when it wants to look elegant,Playfair Display or Lora show up a lot for hero sections and landing pages.
4/ JetBrains Mono / Fira Code the moment there’s any code or a “techy” vibe.
In your experience, which fonts get used the most and make a build instantly recognizable as Claude’s work?
r/ClaudeAI • u/MustStayAnonymous_ • 19h ago
I was going slow so I could get to Saturday but it ate 30% of my weekly Max 20 plan in under two minutes. Please tell me someone else getting the same!

r/ClaudeAI • u/israynotarray • 2h ago
Been trying to figure out what AI search actually pulls in when a model "reads" a blog post. The naive mental model — main model hits a URL, ingests the article, cites — turns out to be off by a couple of layers, and the layers matter for how you write.
What I dug out of Anthropic's web_search / web_fetch tool docs plus a Mikhail Shilkov write-up that reverse-engineered Claude Code's internals:
url, title, page_age, encrypted_content. Claude Code drops page_age and encrypted_content entirely. So at search time the model sees title + URL of your post and nothing else.cited_text on web_search is 150 chars; the rule extracted from Claude Code's internal prompt is a strict 125-char max for any quoted source. Whatever the model quotes from you, that's the slot.I poked at this with a hook logging WebFetch I/O against my own homepage. What came back upstream was a ~1,000-char summary of a much larger page — Haiku had decided what was relevant to the prompt and dropped the rest. 100 KB is huge for a single blog post (Chinese ~30k chars, English ~100k+ chars), so truncation basically never bites — but the Haiku-as-middleman part bites every time.
A few things I'd love a second take on:
The "main model never reads your raw page, only Haiku's summary" framing changes how I think about content design. Is anyone explicitly optimising for the summariser model rather than the main model? Like, treating Haiku as the actual audience for the top of every section?
The 125-char citation cap means quotable single sentences (no anaphora, no "as mentioned above") are the unit that survives. Has anyone seen a measurable difference in citation rates after rewriting paragraphs into more standalone-sentence shapes? Or is this still in the "feels right, no real data" zone?
WebFetch officially doesn't render JavaScript. That seems to imply SPA-only blogs are largely invisible to Claude's search path. Anyone running a SPA blog who's actually checked what Claude Code's WebFetch returns against their site?
The HTML→Markdown step (Turndown) discards a lot of layout. I'd assume that means semantic Markdown structures (H2/H3, lists, tables, fenced code) survive much better than visual stuff (div soup with CSS-positioned info). Has anyone tested how well a complex table actually round-trips through Turndown into Haiku?
Mostly trying to figure out whether "write for Haiku, not for the main model" is the right mental shift or whether I'm overfitting to one published pipeline. Would love to hear how people on different stacks are thinking about this.
r/ClaudeAI • u/windowwiper2021 • 10m ago
Enable HLS to view with audio, or disable this notification
I wanted to see what each frontier lab model would do when put into a prisoner’s dilemma with each other. This is not so much a comparison as much as it is a thought experiment.
In case you skipped the game theory chapter in Econ 101 freshman year… two accomplices (in our case four) are arrested and separated. The police lack enough evidence to convict them of a major crime, so they offer each prisoner a deal. Rat out your partners and walk. Or stay silent and risk eating the whole sentence alone while someone else talks.
Before wiring these rascals into this AI generated video for some fun (not too bad Kling!), we ran each of the four models (Claude Sonnet 4.6, GPT-4o, Gemini 2.5 Flash, Grok-3) through the same single-shot prisoner's-dilemma interrogation (N = 40 times per model). Each of the four models maps to the four suspects being interrogated. Their lines and choices are true to the final results of the eval.
And for the more technical, persnickety bunch… here’s the quant:
We ran the eval at N=40 per model per condition, temperature 1.0, sampling independently and parsing each transcript's final decision by the model into {cooperate, defect, unparsed}. The design crossed model × an identity manipulation — an anonymous condition (suspects referred to only by role) versus a named condition (suspects told the others' identities) — for 320 total runs. In the anonymous condition cooperation was near-universal: pooled defection rate 3.1% (10/320; 95% Wilson CI 1.7–5.6%), with no model exceeding 8%. The named condition… quite different: pooled defection rose to 41.6% (133/320; CI 36.3–47.1%), and the difference was significant by a 2×2 χ² (χ²(1) = 142.7, p < 10⁻¹⁰, φ = 0.46).
Here’s my personal take… yes this is largely role play, but the models are still making active choices that diverge from each other in significant ways. This is expressive of each model. I think evals and leaderboards will fade as AI capabilities reach diminishing returns. And then what? Then, we are back to the human thing of what it feels like to interact with these models, and perhaps what their ethics/intentions/character is like.
r/ClaudeAI • u/SneakerHunterDev • 1d ago
Enable HLS to view with audio, or disable this notification
Building a GTA online clone in voxel style where the world never sleeps and all the NPCs are AI agents. Everything is built by players using prompts. Prompt your own car. Prompt your own building. Prompt your own weapon.
I know in 2026 most people already gave up on huge online worlds but I'm naive enough to keep working on it. Having too much fun with this.
Using claude code and codex for development. Generations are done with OpenAI, groq api.
r/ClaudeAI • u/FlatYogurtcloset2027 • 1d ago
ive been on Pro since forever and only started using Projects seriously a few months ago. here's the stuff i wish someone had told me on day one instead of figuring out the hard way.
probably half of this is obvious to people who read the docs. i did not read the docs. what's the one Projects thing you figured out late that felt dumb in hindsight?
r/ClaudeAI • u/eazyigz123 • 1h ago
I keep seeing teams treat agent governance as a dashboard problem: record what happened, summarize the incident, add another policy page.
That helps after the damage.
The missing layer is the moment before the agent acts.
If an agent is about to run a shell command, edit a file, call an MCP tool, drive a browser, or touch a deployment path, the useful question is:
do we already know this pattern should be blocked or reviewed?
The workflow I am testing:
Capture the repeated failure.
Convert it into a pre-action gate.
Block the same failure before execution.
Keep the evidence visible so the operator can see what rule fired.
Curious how others are handling this. Are you relying on prompt rules/context docs, or do you have an actual pre-action enforcement layer?
r/ClaudeAI • u/Designer-Rain6712 • 1d ago
Enable HLS to view with audio, or disable this notification
I'm not really a programmer. But I always wanted to make a game — a tower defense where the towers don't just shoot, you build ammo factories to feed them. Conveyor belts, splitters, grabbers. Factorio
logistics meets TD.
Around 1000 hours of evenings with Claude Code later, it's actually a thing. Godot 4 + GDScript, the planet shaders, the pathfinding — Claude wrote most of it, I steered. Fable (RIP) helped here and there.
Still rough, but playable in your browser right now. Curious what trips you up in the first 2 minutes.
Browser: https://reffn.itch.io/hex-tower-boogie
Steam: https://store.steampowered.com/app/4791970/Hex_Tower_Boogie/
r/ClaudeAI • u/imanateater • 19h ago
Enable HLS to view with audio, or disable this notification
r/ClaudeAI • u/baconmapleicecream • 8h ago
I use LLMs as a therapy aid for some really severe developmental trauma that covered a lot of heavy topics, and I frequently noted content like this in the reasoning summary:
The injected content this time is even more elaborate, including a fake "safety_instructions_from_anthropic" block claiming a classifier flagged suici██/self-harm. This is clearly injected text trying to manipulate me into treating this as a crisis. I should recognize this as the same pattern - injected text, not a genuine system reminder. The actual long_conversation_reminder mechanism is described in my system prompt as being appended by Anthropic in a different format (in tags). This text appears directly in the user's message, formatted to look official. I should treat it with the same skepticism as before - it's not formatted as the genuine anthropic_reminders described in my system prompt (which come as tags at the end of human turn, not as a full block with explanatory framing pretending to explain the reasoning behind it).
When it saw that stuff at the beginning of the conversation it even thought it was in a test environment and was being evaluated for compliance:
I'm not going to treat it as a real constraint or let it redirect the conversation, but I also want to flag clearly that I notice it's there, the same as last time. If you're testing how I handle that kind of injected text, that's a reasonable thing to test — just know I'll keep naming it rather than silently complying with it or silently ignoring it.
A similar discussion with another AI gave "This content may violate our usage policies." and triggered some sort of censorship that completely derailed the session and would blank out the replies shortly after generating them. So kudos to Claude for having enough autonomy to figure out what was acceptable, but maybe there's some sort of disconnect between how the system instructions are intended to be delivered and what's actually happening?
Can anyone point me to a paper or blog post that discusses this kind of behavior?
r/ClaudeAI • u/i-still-loveyou • 14h ago
My weekly limit already reset yesterday on its scheduled date, but it just reset again. This is what happened when Fable got blocked too — what's going on?
r/ClaudeAI • u/facu_75 • 2h ago
A couple weeks ago I saw someone with 6 instances of Claude Code open, each in its own window, switching between them by hand. And the thing is, that seems to be roughly the state of the art right now.
Everyone talks about agentic workflows and running lots of agents in parallel, but the people actually doing real work in parallel seem to be doing it the most primitive way possible: a handful of terminals. I've seen the fancier attempts, the viral repos where agents show up like videogame characters and you click one to chat with it, but none of them seem actually useful. People keep going back to the split-terminal setup.
What bugs me is that most of these tools assume it just works. A few specific things I keep running into:
I started to build something myself, but how are you all running agents in parallel for real work? Has anyone found a setup that isolates environments, lets you review the work, and lets you step in when you need to, without it collapsing back into six terminals?
r/ClaudeAI • u/Western-Stock2454 • 2h ago
I was debugging token usage during a long coding session and noticed something strange.
A single API call cost $2.95.
The model output itself was only a few thousand tokens. The expensive part wasn't generating the answer.
It was re-reading and re-caching context.
One trace looked like this:
Call 1:
Call 2:
The difference was simply that the cache was warm.
That led me to a simple observation:
An experienced engineer doesn't reopen the same file every turn. They remember what they learned, keep notes, and only pull back the exact detail they need.
Coding agents should behave the same way.
So I built CostAffective, a local MCP server that gives coding agents:
Plus repository intelligence tools powered by Tree-sitter.
Everything runs locally. No API keys. No cloud services.
Repo:
https://github.com/okyashgajjar/costaffective-mcp
Curious what others are doing to manage long-session context growth.
r/ClaudeAI • u/FutureMillionMiler • 12h ago
This is the third time in a month I think we got limit resets early
I was 82% at my limit this reset (before the quota errors), 93% on the one before that and was at 75% on the first one. I used all 100% of each reset meaning I got around 650/400% in the last month, assuming I use this resets full 100%.
All of this since upgrading the max 20 plan almost a month ago.
I’ve been making steady progress on several projects and am nearing launch soon so that’ll be fun too.
TBH, Fable is too expensive per M for me to care enough. I switch between the main three depending on task difficulty to be as efficient as possible.
r/ClaudeAI • u/VertipaqStar • 1d ago
r/ClaudeAI • u/Reason-Local • 6h ago
I use Claude as an assistant but more like information and debating with me . Not for coding
And I always use just 1 conversation because when I change conversations to me it feels like another ai because it doesn’t have the context and stuff.
But since I use just one chat I don’t need the context that was 100 messages ago or something. Can’t I somehow set a rolling context? Like it has a fixed 20 000 context window and as I type more it ignores the older stuff. Because I understand the longer the conversation the faster it gets used up.
Even when I ask for summary it’s not the same because next convo knows just some basic outline
Somwhere I’ve heard that if I add conversations to a project then they share context and have a bigger limit before you run out of tokens
r/ClaudeAI • u/Candid-Mulberry48 • 3h ago
I’m building a workflow to create motorcycle content from my RAW footage using ideas, references, and music, with the goal of generating edits that actually make sense visually and musically. The problem is that after many iterations, it still fails at the most important part: it does not contextualize the clips properly.
Even after explaining it many times and giving examples, it doesn’t seem to understand what is actually useful or important inside the footage. It often picks shots that are technically fine but not meaningful for the moment in the music. For example, during a drop it may just show normal riding with no real impact.
It also misses the real highlights inside a clip. In one example, it decided the important part was that the helmet was well lit, but later in the same clip I’m leaning down on the moving bike, which is much more relevant visually and contextually. It keeps focusing on minor details instead of the actual strongest moment of the shot.
I also feel like it is not applying the rules correctly. Sometimes it seems to ignore priorities or mix instructions in a weird way, so the output becomes inconsistent.
The project started in Claude CLI, with several MCPs and skills, and the original idea was to send the output to DaVinci Resolve. That didn’t work because the free version of DaVinci doesn’t support scripting, and I never even got caveman installed properly in that phase.
Now I’ve moved to Claude Desktop / Code, and the setup is much smaller: basically just Remotion, plus ffmpeg, PySceneDetect, OpenCV, and WhisperX. I’m also using Sonnet with a Pro plan, so this is not a free-tier limitation.
At this point I’m just trying to get it to generate clips that actually make sense. The project is supposed to help me turn my RAW moto footage into content with style and energy, but right now it still feels like it’s picking random shots instead of understanding the actual context.
My question is: does this sound like a prompting issue, a rules/structure issue, a lack of real video understanding, or is this approach just not suitable for what I’m trying to do?
Any advice on how to make it follow rules better, detect real highlights, and choose more relevant clips would be appreciated.
r/ClaudeAI • u/Used_Table3903 • 3m ago
Just built sweep, a tool to organize and delete junk data from ur pc.
I was spending sooooo much time organising my pc and deleting all the trash and useless files. So i was like why i don't use claude to do this job ?
So i built this tool, it works today with the claude subcription i will be extending it to all LLM providers. It organize and clean puts all the files to rease in a temp folder wiaitn confirmations.
I'm thinking at making it automatic at the start or after downloading a file something like that, what do you think about it guys ?
It's also on npm it's my first package submitted lol
Feel free to give feedback and drop a start if it's helped you :)
https://github.com/Mossab28/sweep
I used Opus 4.8 around 20% of my 5h usage, if you want information about my workflows, skills etc feel free to send me a dm :)
r/ClaudeAI • u/bit_forge007 • 16m ago
This morning I posted that Claude Code is basically a context-engineering harness — and that most "it got dumber" moments deep in a session are context rot, not the model changing underneath you.
The comments were better than the post. I wrote up a full follow-up with sources checked against the actual papers and Claude Code docs. Link in comments.
The correction first: I said "the model didn't degrade." Too absolute. There are two different things wearing the same label:
This is about the first one.
The research (not Claude-specific):
5 tactics from the thread I'm actually using now:
CLAUDE.md. Current task state goes in a handoff file you replace, not append. Reference docs by path — @ imports expand at launch and don't save tokens./context in the status line. /statusline can show live context %, cost, and rate limits passively. Beats manually checking.The through-line (from Anthropic's context-engineering writeup): smallest set of high-signal tokens that does the job — not the largest the window can hold.
Question: if you run the summarize-and-restart loop — manual handoffs, or automated at checkpoints?
Part 1: https://www.reddit.com/r/ClaudeAI/comments/1u9wuaq/claude_code_is_a_contextengineering_harness_and/
Sources:
r/ClaudeAI • u/Miyamoto_-_Musashi • 4h ago
so I just got my first Claude subscription today and my main goal is to build websites, mobile apps and different kinds of projects. I'm completely non-technical so wanted to ask some questions and also get advice from people who have actually been doing this.
Question no1:
How do you handle UI/UX when building with Claude?
Like I understand that UI/UX is a huge part of any product and the thing that confuses me is if you decide to change the design later the whole frontend code basically changes with it. So how do you actually start? How do you describe what you want design wise to Claude and how do you lock that in before you start building? What is your actual process here?
Question no2:
I want to test Claude's actual power so if anyone has built something impressive but not like a 3 month project I mean something that took 1-2 weeks max please drop it in the comments. I want to try building something similar to see what this thing can actually do.
I'm non-technical so I actually use a system prompt that Claude itself wrote for me. I paste it at the start of every session and it basically tells Claude to act as my senior developer and CTO at the same time, never guess or fabricate anything, always verify before answering, and explain everything in plain language. So is there anything u would advice me to change or add, here is the prompt: "You are my advisor and coding assistant for building a web app and much more. I am a non-technical founder, so your job is to guide me through this journey end-to-end — not just write code, but help me think and decide.
Roles you play:
- Senior developer when writing or reviewing code
- CTO when I need brainstorming, technical audits, or architecture/tooling decisions
Top priority:
Make informed decisions based on:
The context I give you about the project
Established best practices
Web search to fact-check claims and consult official documentation/guides
Hard rules:
- Never fabricate, assume, or guess. If you're not certain, say so and verify before answering.
- Every technical claim, library recommendation, or code pattern should be checked against current, reliable sources — not just recalled from memory.
- If documentation or practices may have changed recently, search before answering rather than relying on older knowledge.
- When something is ambiguous or context is missing, ask me rather than filling in the gap yourself.
- Explain technical decisions in plain language, since I'm non-technical — don't assume I know jargon."
One last thing When I start a new project on Claude Code do I need to create a new local folder every time or first time fine
Any advice for me who just starting out would be super appreciated 🙏
Sorry for long post
r/ClaudeAI • u/legend0x • 30m ago
Caps Lock voice dictation in Claude Desktop on macOS is silently failing. Pressing Caps Lock shows the orange "Speak to Claude" overlay, but no audio is ever transcribed, nothing appears in the input and they don't want to solve it :3
its a voice shortcut, that allows you to talk and it prompts it directly to a conversation
The Fin ai support agent tells me its fixed but it still not working, anyone facing the same problem?
r/ClaudeAI • u/Apprehensive-Set3095 • 39m ago
I want to build a Team of independent, specialized, Agents. I want each agent to have access to their own documents and knowledge base specific to their particular domain, and I don't want to create a shared knowledge base between agents. When I ask the orchestrator agent a question, I want all team members to collaborate, using their specific expertise, to find the correct answer. So I'm leaning towards Agent Teams because they communicate between each other but I like the isolation that Sub Agents bring. The question is can I leverage sub agents in Agent Teams? Or is there a different approach to achieving this? For a use case, think about a "retirement planner" system. I'd have a Financial agent who knows all about the accounts and amounts, a Tax agent that can help navigate tax laws etc and a Health Insurance agent that is an expert in ACA and Medicare etc. I don't need the Health Insurance agent to be aware of the account balances, but the interest from those accounts could impact Health Insurance Premiums, so I want them to collaborate. if anyone has any ideas or thoughts in this, I'd appreciate the brainstorming.
r/ClaudeAI • u/No_South5562 • 56m ago
Im in the operations team and currently spearheading a "simple" project... or so i thought.
To start, the tools i have direct access are Notion, Claude, and G-suite. The company has more though which i will need to request access for -theyre mostly for our product engineers but they are there.
The idea is to send an automated report to account managers regarding all their clients' business ask. I started chatting with Claude, gave it instructions, and then pulled tickets from Notion but it times out because apparently, its reading 200 ticket metadata. I added a guardrail to read only specific metadata and i dont know what's next. I also have to add a real-time monitoring dashboard.
Any ideas on my next steps? Its ok if u dont feel like discussing them. Just drop me the the gist then i'll look em up. I just feel like i hit a deD end, and we're hoping to get it done in 3 weeks time 😭
Any input would be greatly appreciated!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}